

#27 Por la IA muere el pez
Si no eras bueno tomando decisiones, la IA te hará peor
A veces uno se levanta optimista de buena mañana.
Los cada vez más listos modelos de IA en modo “deep research” extraen en un tiempo ridículo conclusiones de cientos de fuentes publicadas. Son una herramienta poderosa cuando no tienes contexto sobre algo que te llevaría muchas horas estudiar.
El problema de los modelos es tu ventaja: que no tienen contexto sobre la situación en la que tú tienes que aplicar el conocimiento que te acaban de facilitar.
Y eso es bueno y malo a la vez: antes y después de la IA, siempre llega ese momento en el que tienes que tomar una decisión: más información sólo va a servir para diferir tan terrible momento, no para facilitarlo.
Los buenos decision makers van a salir ultrafortalecidos con estas herramientas.
Los malos, se van a limitar a preguntarle todo a su modelo favorito.
Y esto último, antes y después de la IA, siempre ha tenido muuchos costes y servidumbres.
Estás leyendo ZERO PARTY DATA. La newsletter sobre actualidad, tecnopolios y derecho de Jorge García Herrero y Darío López Rincón.
En los ratos libres que nos deja esta newsletter, nos gusta resolver movidas complicadas en protección de datos personales. Si tienes de alguna de esas, haznos así con la manita. O contáctanos por correo en jgh(arroba)jorgegarciaherrero.com
¡Gracias por leer Zero Party Data! Apúntate!
🗞️Noticias del Mundodato 🌍
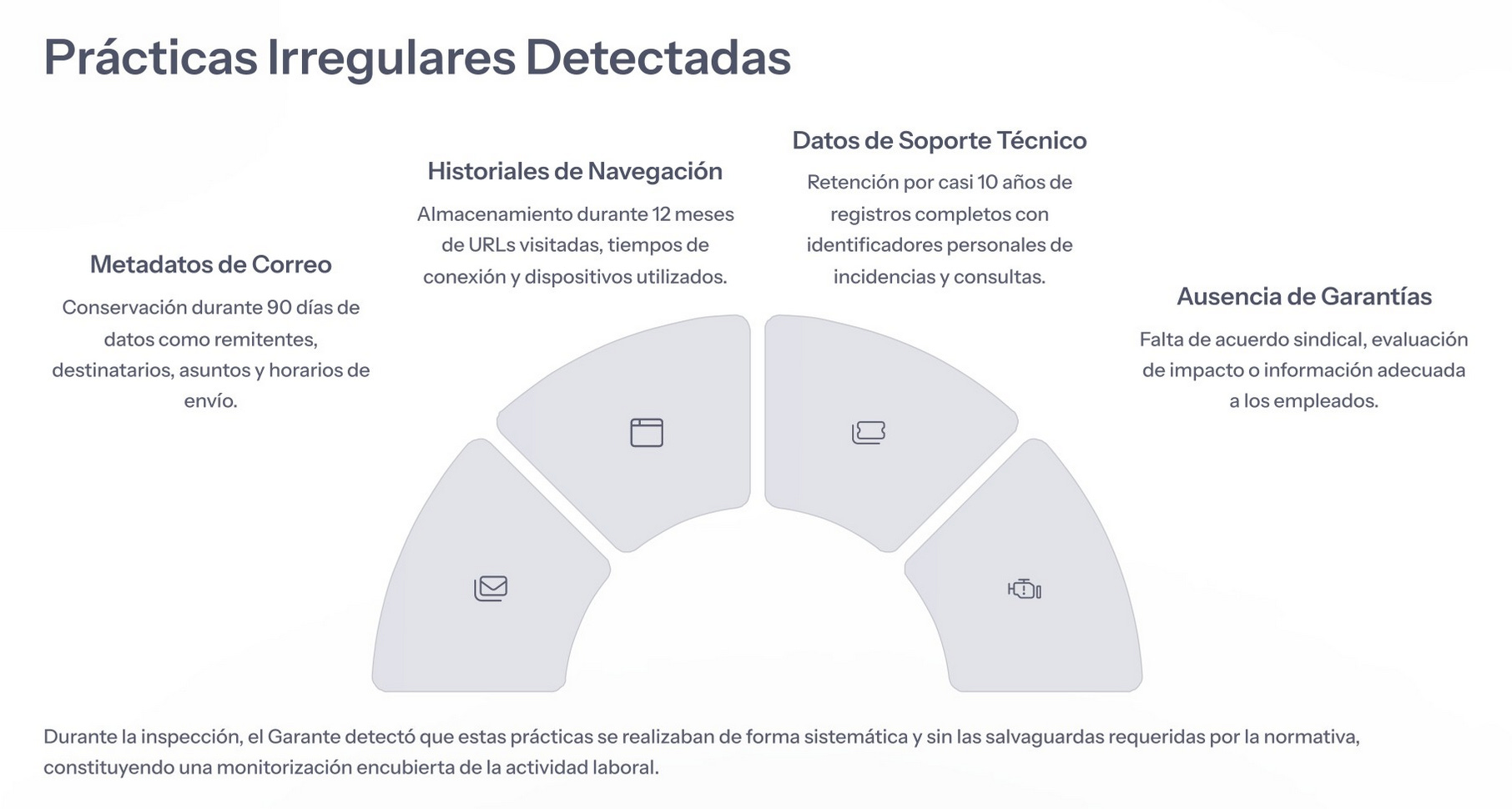
.- De la sanción a Lombardía por conservación de metadatos de correos electrónicos de su personal, nos hemos encontrado por Linkedin unas diapositivas que explican claro el contexto y el desglose de infracción: minimización, limitación del plazo de conservación, no PIA o falta de base del 6 adecuada. Cortesía de Olga María Martínez Rodríguez.
.- La AEPD tradujo a castellano en abril de este año la guía de datos sintéticos de la autoridad de Singapur, y ahora va a tener que darle a la nueva versión que sacó la semana pasada sobre anonimización (la sacó la asociación regional de autoridades de PD, pero para entendernos). Lo de nueva versión, viene porque ya teníamos una 1ª en solitario de la autoridad de Singapur traducida en 2022.
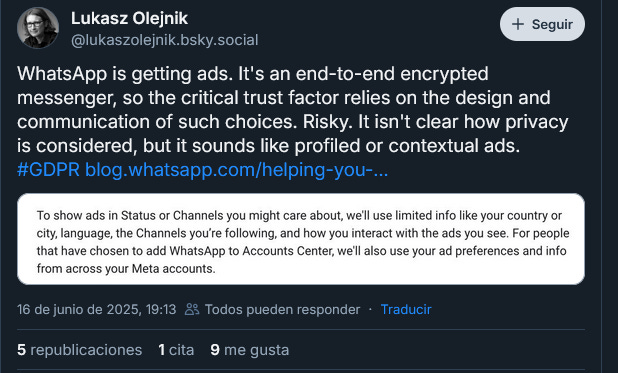
.- Qué bien. Meta haciendo más por llevarse el premio de buenas prácticas.
.- Joan Westenberg le da la vuelta al concepto de “Tsundoku” -la palabra japonesa para ese afán de acumular libros y artículos que no leerás ni en tres vidas-: “Eliminar me enseñó a vivir las ideas, no a gestionarlas. Eliminé todo. Todas las notas en Obsidian y mis "segundos cerebros" cuidadosamente construidos. Todas las Notas de Apple y listas de tareas pendientes. Todos los artículos en mi lista "leer más tarde". Todos los sistemas productivos que había creado a lo largo de los años. Sin embargo, no sentí pánico, solo alivio. Los sistemas de captura de todo pueden convertirse en mausoleos de nuestros yo pasados y curiosidades antiguas. La promesa es crear una red tan vasta que responda preguntas antes de que se hagan, pero la realidad es que la memoria humana funciona de manera asociativa, emocional y viva.”
Un post profundo y relevante. Léelo, no te limites a bookmarkearlo.
.- El juicio al violador y asesino de Narón (Coruña) hace resurgir una de mis historias favoritas de protección de datos personales: su detención puso en el sitio que le correspondía a aquella famosa sentencia (mejor decir “fallo”) de nuestro Tribunal Supremo que declaró que los libros bautismales no eran “ficheros de datos”.
📄Documentos dateros-muy-cafeteros☕️
.- Del mismo jueves que se lanzó la anterior newsletter, viene proyecto de recomendaciones sobre tracking pixel en correo electrónico de la CNIL (y la nota de prensa). Interesante leerlo entero, pero como highlights:
Aterrizar las figuras de responsable, encargado y corresponsable entre la entidad que envía el correo, el gestor de correo electrónico que sea y el proveedor de servicios de “alquiler” de listas de correo y mailing. La líquida caso a caso es la corresponsabilidad, como siempre.
Ejemplos que requieren el consentimiento que amerita como base general:
Medición y análisis individual de las tasas de apertura de los correos electrónicos para: evaluar y mejorar el rendimiento de la campaña (por ejemplo, ajustando las líneas de asunto del mensaje en caso de una tasa de apertura baja o mejorando la relevancia, legibilidad o atractivo de la línea de asunto del correo electrónico); y/o adaptar la frecuencia o detener el envío para mantener la capacidad de entrega de las campañas,
Creación de perfiles de destinatarios basados en sus preferencias e interés para personalizar correos, o
Detección y el análisis de sospechas de fraude.
Ejemplos que considera la CNIL que están exentos de consentimiento. Que nadie se haga ilusiones, que es un poco como la guía de cookies de analítica exentas de la AEPD.
Único fin de aplicar medida de seguridad de autenticación (por ejemplo, enlace de restablecimiento de contraseña que se abre en dispositivo validado y conocido del usuario), o
Medición de la tasa global de apertura del correo electrónico que permita saber si se entregan correctamente, pero limitado a: estadístico y agregado sin medición individualizada, y aplicable a correos solicitados por el usuario/relacionados con servicio solicitado por el usuario.
Ejemplos de literales y de cómo obtener el consentimiento. Y un recordatorio final de que no se intente confundir con el consentimiento para el envío del correo.


.- Cristina Ayo Ferrándiz, Pablo González Guillén e Ignacio Garre Anguera de Sojo han escrito un buen doc sobre responsabilidad civil en el contexto de las IAs, especialmente relevante al habernos quedado de pronto compuestos y sin la directiva de armonización que iba a clarificar esta materia.
.- El libro de Karen Hao, Empire of AI: investiga el desarrollo de grandes modelos de lenguaje como ChatGPT y destaca la exageración que impulsa el negocio de la inteligencia artificial. Los grandes modelos de lenguaje no piensan ni sienten, sólo producen textos mediante conjeturas estadísticas. Sin embargo, muchas personas no comprenden este concepto, lo que produce una "psicosis inducida por ChatGPT". Hao enfatiza que el impacto de la inteligencia artificial no es inevitable y que es necesario entender su potencial y limitaciones para evitar las peores consecuencias.
💀Death by Meme🤣

🤖NoRobots.txt o Lo de la IA
.- El centro de investigación de la Comisión Europea se sacado de la chistera otro documento sobre GAI: “Generative AI Outlook Report”. No es un documento desde el punto de vista técnico, sino general o tipo bosque (ya incendiado). No obstante, sí tiene alguna cosa que merece atención:
Enlace a los informes de evaluación de riesgo sistémico DSA de Linkedin, X, TikTok, Bing, Facebook o Instagram (pie de página, pág. 90), y la de Google en el pie de la 92. Vaya ironía que es que los enlaces de META sean los únicos que no funcionan.
Enlace a resoluciones de las sanciones a Chatgpt, Clearview y + que sirve como suerte de repositorio. También de documentos interesantes de autoridades. Lo más interesante están las notas a pie a partir de esa 92 mencionada.
La captura de la nueva carrera armamentística para meter IA en lo que sea. Cada mes que pasa en el loco mundo parece un año entero, pero no ha llovido tanto desde el boom de DeepSeek.
.- Buena panorámica del Señor Montezuma sobre distintas guidelines y cosas a tener en cuenta a la hora de determinar los roles (y obligaciones afectas) a todas las partes que meten cuchara en un flow de datos personales entreverado con IA.
La ICO subraya que el iter no se queda en el ciclo de vida de la IA sino que incluye la resolución de problemas, la mejora del modelo y la creación de nuevas aplicaciones y servicios.
.- How much do language models memorize? De John X. Morris, Chawin Sitawarin: un paper que ya no se pregunta si los modelos memorizan datos: propone varios métodos para evaluar esa memorización: el de extracción, y el retention quantifier.
.- El inside scoop de la semana de Luca Bertuzzi es éste: La Comisión Europea se dispone a (uhm) aclarar en las próximas directrices sobre sistemas de IA de alto riesgo si los fabricantes de productos con funciones de IA integradas deben estar y pasar por ese régimen, incluso cuando utilicen estándares armonizados en lugar de evaluaciones de conformidad por terceros según las leyes sectoriales de seguridad de la UE.
.- Parece que la confederación de autoridades alemanas de protección de datos ha sacado un documento nuevo sobre medidas técnicas y organizativas para el desarrollo y gestión de sistemas IA. Llama la atención que hablen del “Modelo Estándar de Protección de Datos (SDM)”, aka una metodología para traducir los requisitos legales del RGPD a medidas de seguridad con doc explicativo previo (en alemán, eso sí). No tiene mala pinta para lectura de verano a la sombra.
.- Elocuente infografía de Phil Lee que permite hacer decisiones automatizadas sin intervención humana dirimente para dar de paso /no la contratación de IAs de terceros. Te queremos, Phil.
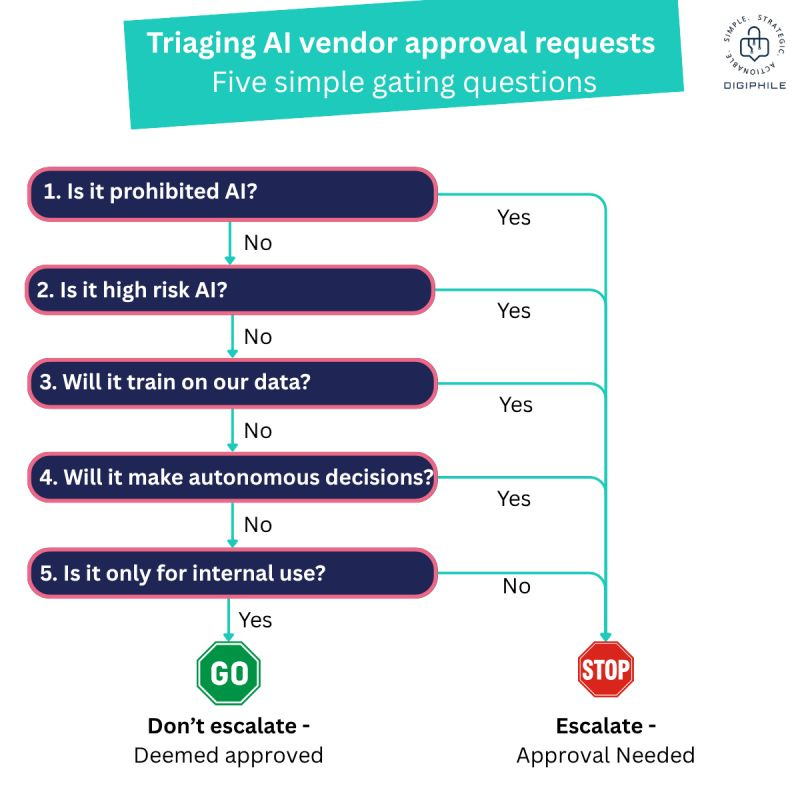
🧷Herramientas Útiles 🔧
.- Este fenomenal post de Thorsten Ball te enseña un truco de trilero para escribir un AI Agent con tus propias manos en menos de 400 líneas. ¿Cómo te quedas?
.- Replikant, mañana.
.- Un acortador de direcciones web, open source, cortesía de Daniel Garcia (cr0hn).
🙄 El chorradon final
Si crees que esta newsletter puede gustar e incluso ser útil a alguien, reenvíasela.
Si echas de menos algun doc, comentario o chorradón que manifiestamente debería haber estado en el Zero Party Data de la semana, escríbenos o deja un comentario y lo valoraremos para la próxima.