

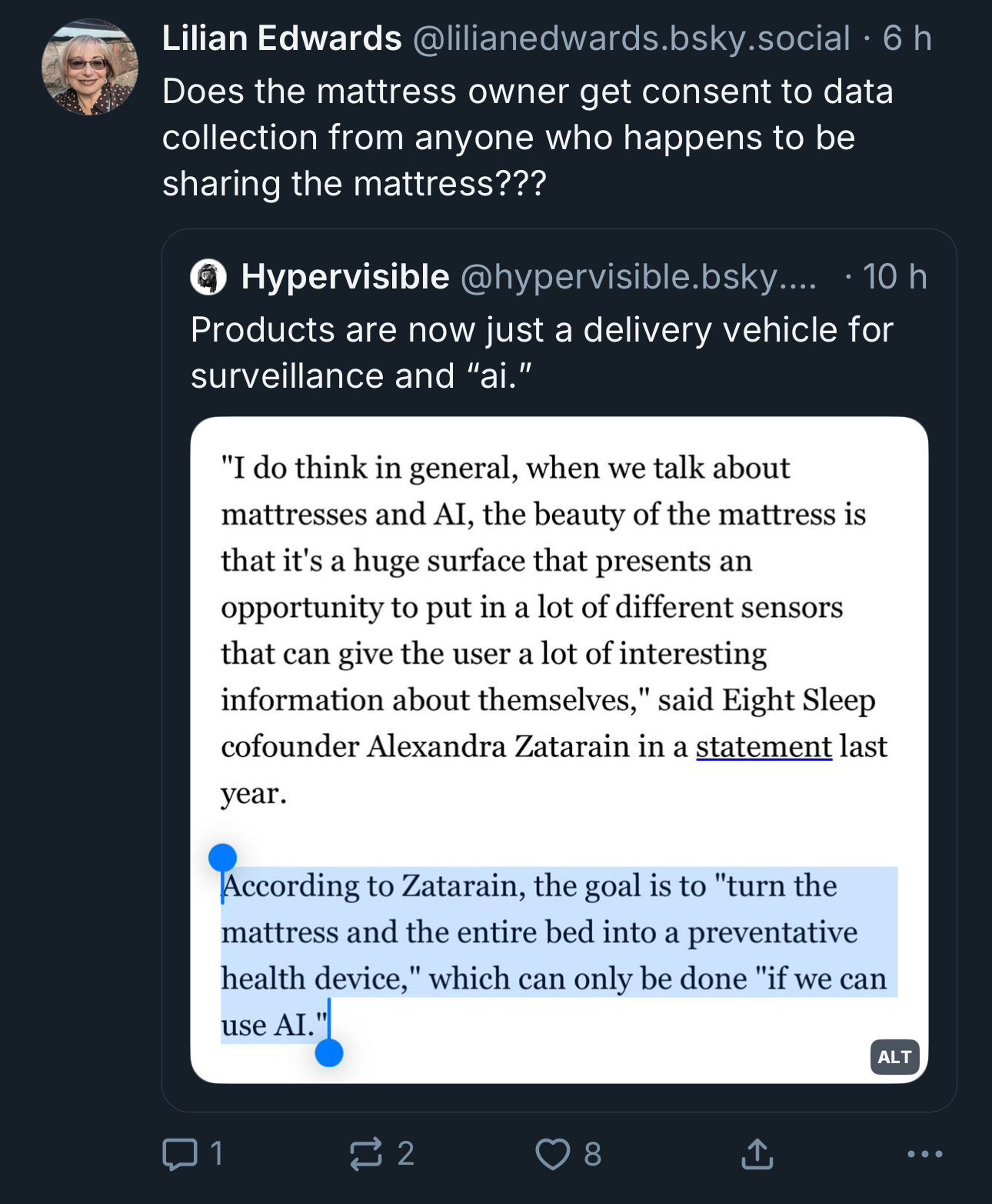
#27 AI will not make you a good decision-maker, I’m afraid.
Quite the opposite, in fact.
Sometimes you wake up feeling optimistic.
The increasingly clever AI models in “deep research” mode can draw conclusions from hundreds of published sources in a ridiculously short time. They’re a powerful tool when you have no context on a topic that would otherwise take you hours to study.
But the problem with these models is your advantage: they have no context about the situation in which you have to apply the knowledge they just handed you.
And that’s both good and bad: before and after AI, there always comes that moment when you have to make a decision. More information will only serve to delay that dreadful moment, not make it any easier.
Good decision makers will come out supercharged with these tools.
The bad ones will just keep asking their favorite model everything.
And that last bit—before and after AI—has always come with plenty of costs and constraints.
You’re reading ZERO PARTY DATA. The newsletter about current events, technopolies, and law by Jorge García Herrero and Darío López Rincón.
In the spare time this newsletter leaves us, we like to tackle tricky problems in personal data protection. If you’ve got one of those, give us a little wave. Or contact us by email at jgh(at)jorgegarciaherrero.com
Thank you for reading Zero Party Data! Sign up!
🕮 News from the DataWorld 🌍
.- In April this year, the AEPD translated into Spanish the synthetic data guide from the Singapore authority, and now they'll have to get to work on the new version released last week on anonymization (issued by the regional data protection authorities association, but you get the idea). “New version” because there was already a first one published solely by the Singapore authority and translated back in 2022.
.- How lovely. Meta doing even more to win the best practices award.
.- Joan Westenberg turns the concept of Tsundoku on its head—the Japanese word for the urge to accumulate books and articles you’ll never read, not even in three lifetimes:
“Deleting taught me to live ideas, not manage them. I deleted everything. Every note in Obsidian and my carefully built 'second brains.' Every Apple Note and to-do list. Every article in my 'read later' list. Every productivity system I had created over the years. Yet I didn’t feel panic, only relief. Capture-everything systems can become mausoleums of our past selves and old curiosities. The promise is to create a network so vast it answers questions before they're asked, but the reality is that human memory works in an associative, emotional, and living way.”
A deep and relevant post. Don’t just bookmark it—read it.
.- The trial of the rapist and murderer in Narón (Galicia) brings back one of my favorite stories about personal data protection: his arrest gave proper context to that infamous ruling (better called a "blunder") by our Supreme Court, which declared that baptismal records were not "data files".
📄High density docs for data junkies☕️
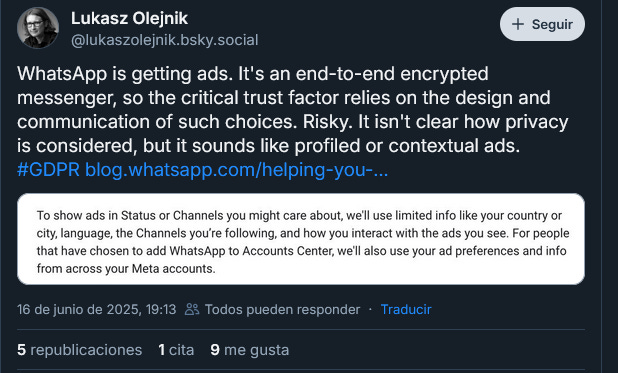
.- From the same Thursday the previous newsletter was released, the CNIL published a draft of recommendations on the use of tracking pixels in emails (along with a press release). It’s worth reading in full, but here are some highlights:
Clarifying the roles of data controller, processor, and joint controller among the entity sending the email, the email service provider, and the service provider offering “rented” mailing lists. As usual, the blurry, case-by-case reality often leads to joint responsibility.
Examples that, according to the CNIL, require consent as a general legal basis:
Measuring and individually analyzing open rates of emails in order to: assess and improve campaign performance (e.g., adjusting subject lines if open rates are low or enhancing the relevance, readability, or appeal of the subject), and/or adapt the frequency or stop sending emails to maintain deliverability.
Profiling recipients based on preferences and interests to personalize emails.
Detecting and analyzing suspected fraud.
Examples the CNIL considers exempt from consent:
Sole purpose of implementing a security measure like authentication (e.g., a password reset link opened on a validated and known device).
Measuring the overall open rate of an email campaign, only if: it is aggregated and statistical, with no individualized tracking, and it applies to user-requested emails or emails related to a service requested by the user.
The document also includes examples of wording and how to obtain valid consent. And a final reminder: don’t try to pass off consent for email delivery as consent for tracking.


.- Cristina Ayo Ferrándiz, Pablo González Guillén e Ignacio Garre Anguera de Sojo have written a solid paper on civil liability in the context of AI—particularly relevant now that we’re suddenly left empty-handed without the harmonization directive that was meant to clarify this matter.
.- Karen Hao’s book Empire of AI investigates the development of large language models like ChatGPT and highlights the hype driving the AI business. Large language models don’t think or feel; they simply generate text through statistical guesswork. Yet many people don’t grasp this concept, leading to what Hao calls “ChatGPT-induced psychosis.” She emphasizes that the impact of artificial intelligence is not inevitable, and that understanding both its potential and its limits is crucial to avoiding the worst outcomes.
💀Death by Meme🤣

🤖NoRobots.txt o the AI stuff
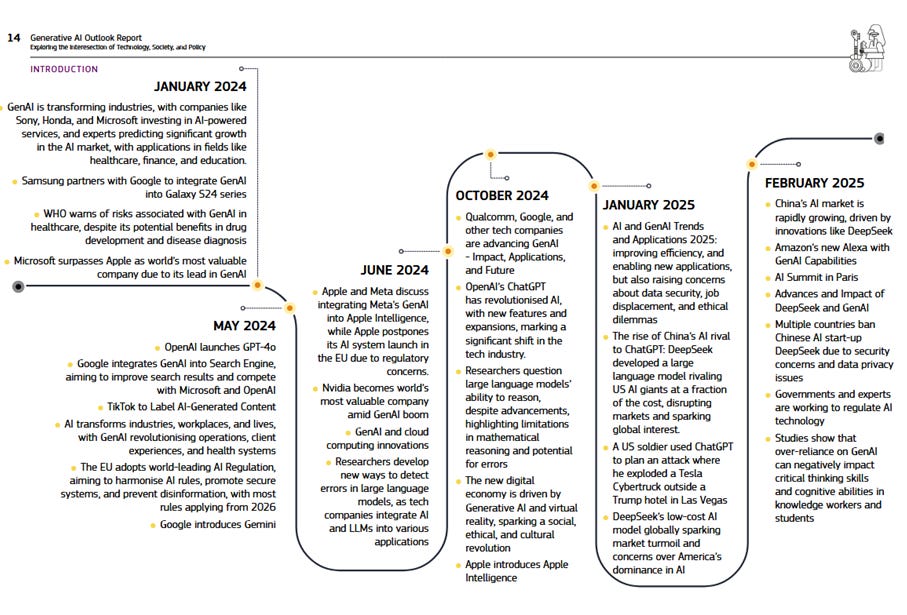
.- The European Commission’s research center has pulled yet another document out of its hat on GAI: the Generative AI Outlook Report. It’s not a technical paper, but more of a broad overview (of a forest that's already on fire). Still, there are a few things worth paying attention to:
There’s a link to the systemic risk assessment reports under the DSA for LinkedIn, X, TikTok, Bing, Facebook, and Instagram (see footnote on page 90), and Google’s is in the footnote on page 92. The irony? META’s are the only links that don’t work.
There’s also a link to resolutions on sanctions against ChatGPT, Clearview, and others, acting as a kind of repository. Plus, links to relevant documents from authorities. The real gems are in the footnotes starting from that mentioned page 92.
The report captures the ongoing arms race to shove AI into anything and everything. Every month in this mad world feels like a whole year, though not that much time has passed since the DeepSeek boom.
.- A solid overview by Mr. Montezuma on various guidelines and key considerations when determining the roles (and corresponding obligations) of all the actors stirring the pot in a flow of personal data infused with AI.
The ICO highlights that the process doesn’t end with the AI lifecycle — it also includes problem-solving, model improvement, and the development of new applications and services.
.- How much do language models memorize? by John X. Morris and Chawin Sitawarin: this paper no longer questions whether models memorize data — it proposes several methods to evaluate that memorization: extraction-based approaches and the “retention quantifier.”
.- Luca Bertuzzi’s inside scoop of the week is this: the European Commission is (ahem) preparing to clarify in its upcoming guidelines on high-risk AI systems whether manufacturers of products with embedded AI functionalities are subject to the same regime — even when they use harmonized standards instead of third-party conformity assessments under EU sectoral safety laws.
.- It seems the German data protection authorities’ confederation has released a new document on technical and organizational measures for the development and management of AI systems. Notably, it mentions the “Standard Data Protection Model (SDM),” a methodology for translating GDPR legal requirements into security measures — complete with a prior explanatory document (in German, naturally). Not bad as summer reading.
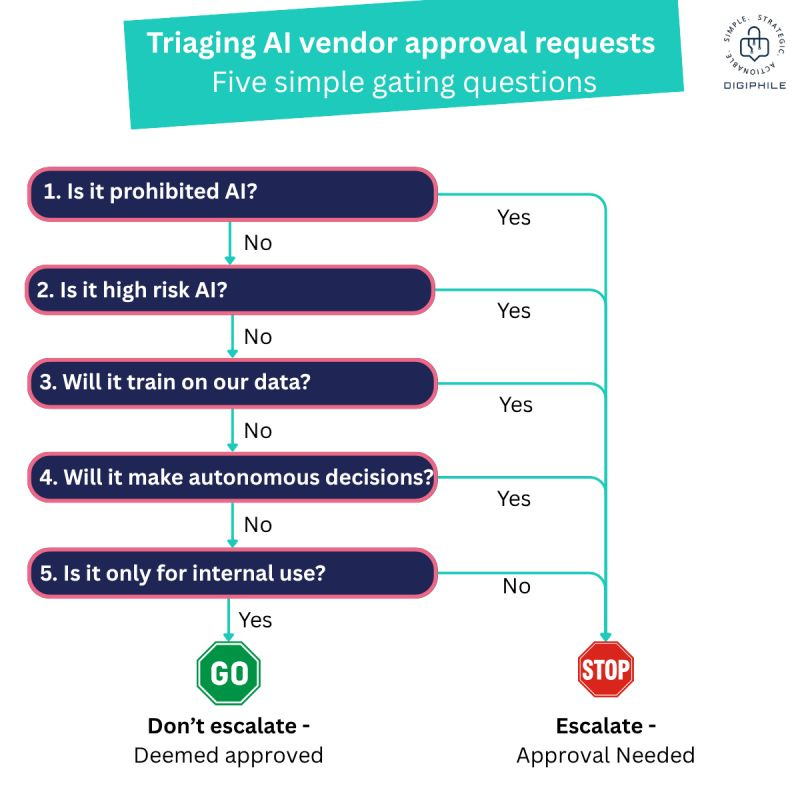
.- A wonderfully clear infographic by Phil Lee that makes it possible to enable automated decision-making without the need for a human to rubber-stamp the use of third-party AIs. We love you, Phil.
🧷Useful Tools 🔧
.- This fantastic post by Thorsten Ball shows you a classic shell game trick to write an AI Agent with your own hands in under 400 lines of code. How about that?
.- An open source URL shortener. Free, customizable and and reliable, by Daniel Garcia (cr0hn)
🙄 Da-Ta-Dum Bass!
If you think someone might like—or even find this newsletter useful—feel free to forward it.
If you miss any document, comment, or bit of nonsense that clearly should have been included in this week’s Zero Party Data, write to us or leave a comment and we’ll consider it for the next edition.