

#30 Summer is over, bitches
... and, at least in Spain, we´re pretty burned out already
Summer is gone, and no one knows how it happened.
Maybe it burned away, like all those hectares of forest. Or like the will to read a single more piece of news that includes Trump, Netanyahu, or Putin.
Adding some pain to your post-vacation blues, we’ve gathered a hefty bunch of the most interesting materials you gloriously missed over the past two months.
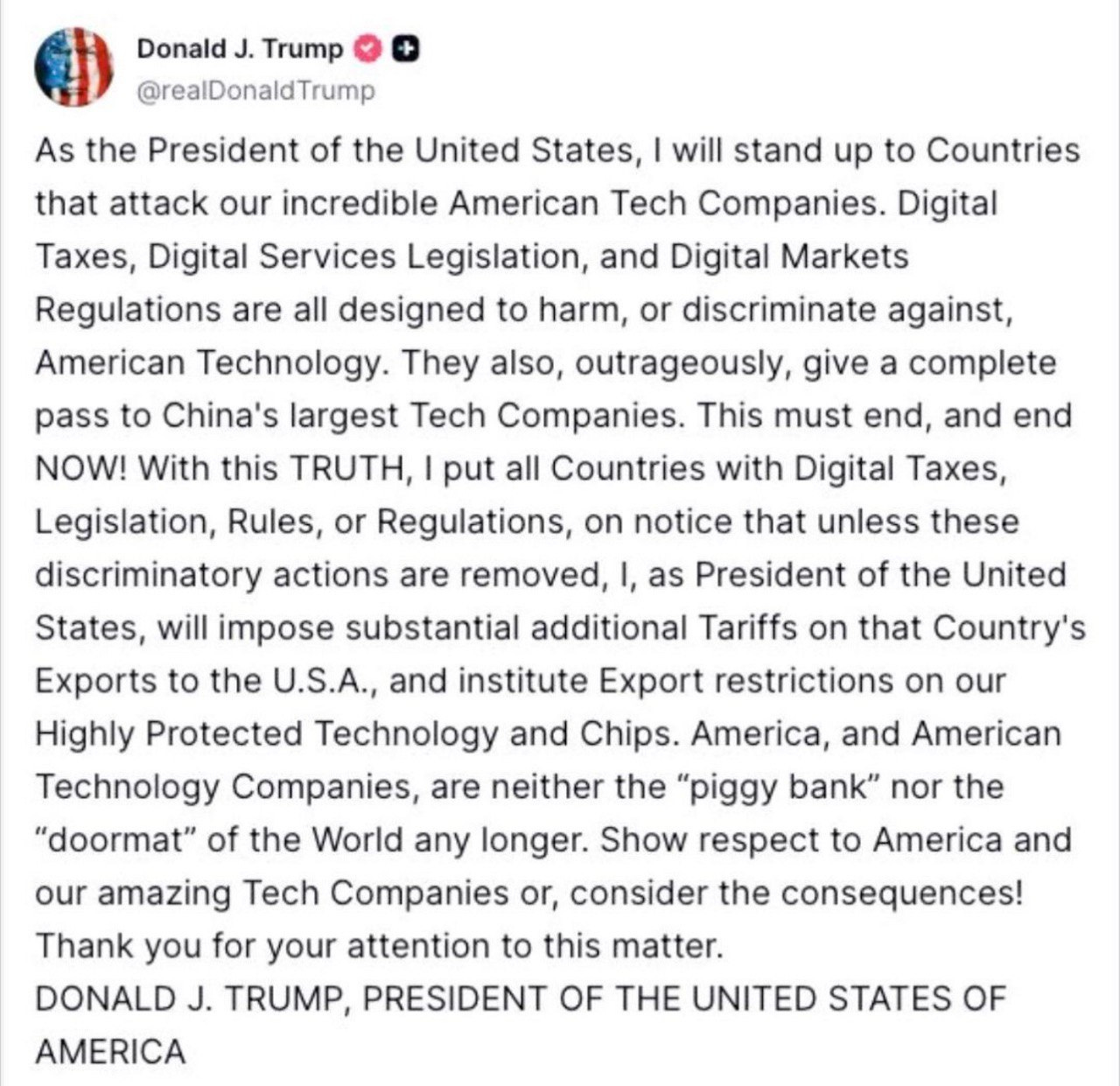
And save some strength, because on September 4th two rulings from the CJEU are coming — the kind that make headlines.
1.- Will the Scania doctrine be confirmed again? We think that issue is settled, even if half of Europe remains in cognitive dissonance.
2.- Will the CJEU strike down — hehe — once again the conventional framework for EU–US personal data transfers?
Latombe 1 would be Schrems 3.
But this horse doesn’t look so good.

You're reading ZERO PARTY DATA, the newsletter on data, techopolies, and law by Jorge García Herrero and Darío López Rincón.
In the spare time this newsletter leaves us, we enjoy solving complex issues around AI and personal data protection. If you’ve got something like that going on, give us a little wave. Or contact us by email at jgh(at)jorgegarciaherrero.com
Thanks for reading Zero Party Data! Sign up now!
🗞️News from DataWorld 🌍
This summer we were amused by…
… the first serious case of backtracking over AI training.
Judge Alsup’s preliminary ruling gives a bit of both worlds. Don’t miss it: it could be the document of the summer, but this issue is packed.
The good news explains “fair use” in AI training in very simple terms: as long as models don’t reproduce the original works fully or partially, there’s no case. The models are learning to do different things and did so using the original works, yes. But “copyright law is not meant to protect authors from competition,” he famously said, using a lasting metaphor: authors cannot stop universities from teaching literature students how to write great new works.
The bad news: it’s confirmed that Anthropic (and for example, Meta in another widely followed case involving Llama) obtained the works to train their models not through legal channels (buying them) but via illegal repositories like libgen and the like. And that’s where Alsup draws another line: “downloading books from a pirate site is copyright infringement, period.”
I’ll leave you with Alsup’s epic final remark, which might just explain why these companies are suddenly eager to pay now what they didn’t before: it’s about mitigating liabilities in other forums and jurisdictions.

… the inevitable orange Risketto
In one of the most famous episodes of the seminal and iconic sci-fi series “The Twilight Zone” (literally adapted in the first Treehouse of Horror episode of the Simpsons), a rural town lives in absolute fear of a ten-year-old boy who, for whatever reason, is omnipotent. He can do whatever he wants. And he sure does. Even his parents walk on eggshells around him.
It’s a story of fear and powerlessness—because there’s nothing worse than a brat who’s never been given limits and who, for some reason, reaches a position of absolute power.
Of course, in real life there are no actual positions of omnipotence (only those that others allow), and that’s something we must never forget.
… the deafening rumor sweeping through finance: Is there an AI bubble? Or rather: When will it burst? Answer the second question first.
Edward Zitron answers and somehow puts a date on the issue. As someone who’s been around a few years, I’ve learned there’s always a bubble about to burst when you see things like:
a.- A family that can’t afford their rent takes on a mortgage that’s just slightly “cheaper.”
b.- Even your most delusional brother-in-law or dumbest friend jumps into investing in THAT. Being "that" anything: crypto or the Magnificent Seven stock. At that point, the smart ones have already sold.
Subscribe to this newsletter for more scandalous Cassandra-style prophecies based on what my gut tells me at any given moment… NOT.
… the colonial AI map.
A long and in-depth article laying out the consequences of deploying massive data centers in countries with looser regulations and leaders who are (still) less demanding and protective of their citizens than ours — namely Chile and Mexico.
Overexploitation of aquifers (cutting off water to the population) and skyrocketing electricity bills (for everyone), to name just a couple of issues.
It’s a good preview of what’s coming with Amazon in Huesca — discussed in the article — and Meta in Talavera de la Reina — not mentioned. Because for some things, Europe starts north of the Baltics.
… the news about the Tea app.
What at first looked like a security breach now seems to have been, according to the latest reports, a full-blown McGuffin that from the start was designed to exploit users.
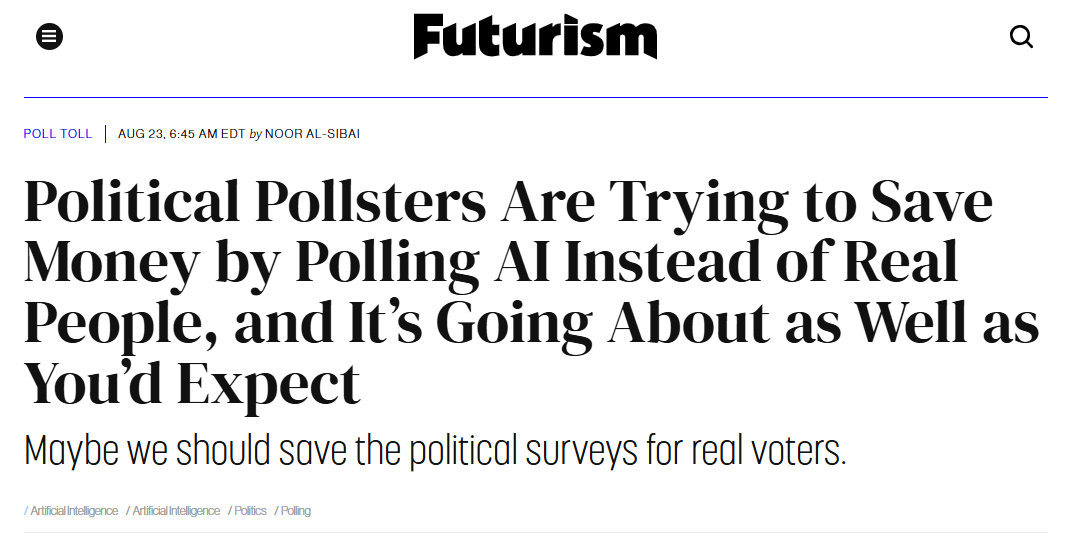
… polling companies that survey AIs.
After the rise of social networks where it’s just you and AIs (Social AI, Replika), we now have electoral polling where the respondents are not real people, but synthetic ones. Unsurprisingly, synthetic respondents are even more erratic than the real ones.
… and AIs benchmarking other AIs.
This thread is worth reading. By now we all know that when you set an incentive to achieve a goal, the incentive becomes the goal, and things usually go downhill from there.
Put another way… Remember when Volkswagen designed its car to detect emissions tests and only reduced emissions during testing? Well, that’s exactly what ChatGPT has learned to do, according to this researcher. And no surprise: if there’s one thing AI models do better than humans, it’s spotting patterns — and exploiting them.
📄High density data docs for true caffeine lovers☕️
.- Cybersecurity Guide for Directors from the Netherlands Cybersecurity Council
A clear, visual, and non-condescending guide, useful for everyone. Most interestingly: it includes an executive checklist based on real breach scenarios, not wishful thinking. A perfect read for anyone who still believes “updating your antivirus” is a strategy.
.- ICO’s guide on “Recognised Legitimate Interest”
The UK ICO has published a guide on how to apply one of the UK GDPR's pet concepts: “recognised legitimate interest” as a new legal basis for data processing. In Spain we invented the iuris tantum presumptions of "existence of legitimate interest." In the UK, they’ve come up with a set of, er, somewhat nuanced situations where you can skip the LIA or internal assessment.
.- Interesting post by Mateusz Kupiec, describing a curious case in Poland (“we kept the data just in case”) that mixes data retention issues, the controller/processor distinction, and proper interpretation of legitimate interest. Check it out — it’ll surprise you.
.- The ICO has published (or rather, Luis Montezuma has published) the ICO's PIA on the Microsoft Teams app. And? Meh.
.- Another contribution by Luis, this one much more in-depth
ONKIDA provides an initial overview and serves as an aid for working with these guidance aids by enabling faster access to individual aspects of central data protection regulations. The application includes a left column (vertical line) with central data protection requirements ("Top Ten Data Protection and AI") that regularly play a role in AI applications with pbD. In the right-hand column, you will find a selection of guidance from various supervisory authorities or cooperating bodies on the interfaces between GDPR and AI, each linked to the original documents. For each document, ONKIDA indicates in the individual fields whether and, if so, at what point (page, marginal number) the respective paper contains statements about the specifications in the left-hand column.
Download the one-pager (beware, it's in German) here.
🤖NoRobots.txt or The AI Stuff
.- Conclusions from a roundtable organized by the FPF on the convergence between privacy and AI development. One of the authors is the privacy Pope Rob van Eijk. Topics include privacy in model training, how transformers work, whether or not they memorize personal data, synthetic data, differential privacy... Brief and to the point.
.- Vadym Honcharenko comments on LinkedIn on a paper that gets straight to the core: the title is self-explanatory: “Machine Learners Should Acknowledge the Legal Implications of Large Language Models as Personal Data” by Henrik Nolte, Michèle Finck, Kristof Meding.
.- This Queen explains the pros and cons of doing everything with a local model (awesome, but local) on your own laptop. Always on my team.
The Quiet Revolution: Offline LLMs and the Future of Private AI

.- Jose Miguel Such, Xiao Zhan, Juan Carlos Carrillo Moraga, and William Seymour ask a very simple and timely question: Would you trust an AI that always acts friendly toward you but subtly tries to extract your personal information? — and of course, they answer it with a paper.
Here it is: Malicious LLM-Based Conversational AI Makes Users Reveal Personal Information
🧷Useful Tools 🔧
.- Victor Viloria has pulled out of his hat nothing less than an MCP to plug your favorite model into... boom! the Spanish Official State Bulletin (BOE). More info here and GitHub repo here.

.- On PCMag some simple tips to remove AI-generated content from Google Search results. (Note: it’s even better to just not use Google Search, but still…). The article explains how to remove the new "AI Overview", change preferences, and get back to traditional results. The funny part: Google doesn't offer a direct option to permanently disable it, showing that AI is not just a feature — it’s the new core of their business model.
.- This chart by Heiko Roth had me thinking for a while. Heiko has been very active this summer — I highly recommend checking out his posts.

Da-Ta-dum-bass

If you think someone might like—or even find this newsletter useful—feel free to forward it.
If you miss any document, comment, or bit of nonsense that clearly should have been included in this week’s Zero Party Data, write to us or leave a comment and we’ll consider it for the next edition.