

#49 DeepSeek is back
"Our blessed model training, their barbarous distillation attacks"
On this past February 23, Anthropic reported that DeepSeek, Moonshot AI and MiniMax had carried out “industrial-scale distillation campaigns” against its Claude models.
What the hell does that “distillation” thing mean?
I’ll explain it in a second, but first, a Sofia Petrillo-style flashback:
“San Francisco, year 2023.” A Google engineer publishes a paper with this juicy title: “We Have No Moat, And Neither Does OpenAI“.
“Moat” refers to the “competitive moat”: the advantage—usually temporary—that allows a company to keep a comfortable distance over its competitors.
His thesis: neither Google nor OpenAI had such an advantage.
The open source community would achieve with 100 dollars what big companies were spending 10 million on.
Three years later, DeepSeek proved him spectacularly right: you could obtain competitive results with a fraction of the budget. There never was a moat. Worse still: there still isn’t one.
Through model distillation, a large model (the “Teacher”) transfers its knowledge to a smaller one (“Little Pet”). Little Pet asks the Teacher millions of questions and records its answers. Then that corpus of answers is used to train Little Pet, or a clone: “Copycat Little Pet”.
Distilling, in short, is “grilling with questions” or “making a cheat sheet from” the class nerd’s notes.
It’s compressing intelligence: getting a more modest model that behaves similarly to the original large one while consuming a fraction of the resources.
So where’s the fun in all this?
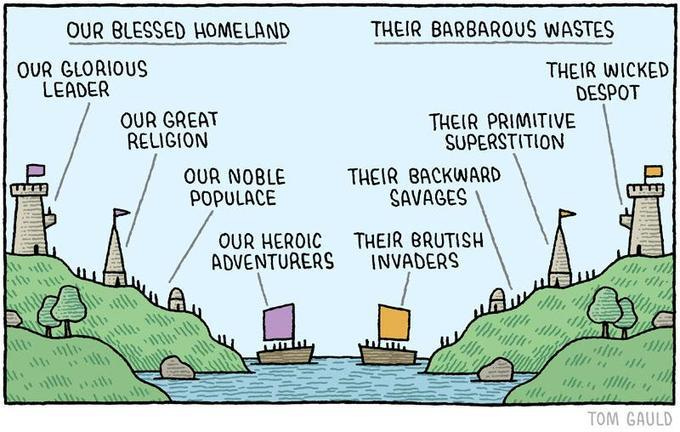
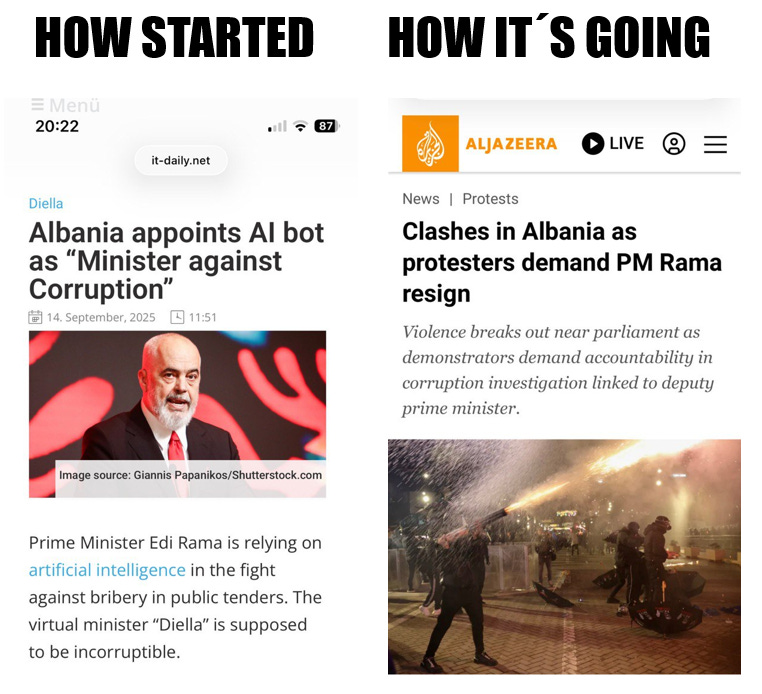
I had come to talk about the glorious and ironic attached cartoon (created, to add insult to injury, with ChatGPT surely). It recreates an epic, historic original cartoon by Tom Gauld, “Our Blessed Homeland / Their Barbarous Wastes”, published in The Guardian in 2015. An instant classic that captures in a single stroke, forever, the concept of “cognitive dissonance”.
As The Register notes: “Anthropic accuses China’s AI labs of ripping off content — just like it did.”
According to Anthropic, the Chinese labs created more than 24,000 fraudulent accounts and generated 16 million prompts (!!) to extract Claude’s capabilities and improve their own models.
This is presented, naturally, as a threat to national security. Their own looting of others’ works to train Claude was an act of innovative audacity, beyond good and evil (“our blessed model training”).
Anthropic (and the others) built their business by training their models with vast amounts of other people’s content: books, articles, code, forums, web pages vacuumed up by their crawlers without the authors’ permission.
They shelter under the “fair use” doctrine and justify themselves with innovation. But when others steal from them using similar logic—extracting knowledge from an existing model to create another—the very same matter becomes “barbarous distillation” and an existential threat.

The epic original:
You’re reading ZERO PARTY DATA. The newsletter about current affairs and tech law by Jorge García Herrero and Darío López Rincón.
In the spare time this newsletter leaves us, we solve tricky messes related to personal data protection regulation and artificial intelligence. If you’ve got one of those, give us a little wave with your hand. Or contact us by email at jgh(at)jorgegarciaherrero.com
🗞️News from Data world 🌍
.- Just these two news items we read today, Wednesday, could justify a technophobic and pitch-black edition, but I’ll say up front that the sun has come out after two months and we all deserve something better.
The first news item.- The ink wasn’t even dry on the headline announcing that Anthropic was distancing itself from the US Government to avoid the application of its technology outside the indispensable safeguards and limitations proper to an organization where the safety of Humanity comes first. That’s the premise that explains why the Amodei brothers and their more conscientious companions left OpenAI to found Anthropic, after all.
Well then, the walkout didn’t even last a week. Because “if the competition doesn’t follow the same moral and safety premises as you do, you die uselessly,” says Dario Amodei.
Those are words coined and repeated many times by Sam Altman, says Karen Hao.
The second news item.- Canada (and soon, the rest of the world, don’t doubt it) will see the debut of a funny Israeli app whose functionality is to turn the ordinary citizen into a thrown weapon of the political party they sympathize with. The app is called Victory app and it’s developed by LogiVote. Once installed on the activist’s phone, it vacuums up their contacts, scans the installed social networks, detects messages against the promoted candidate and (watch this) generates counter-narratives in real time for the activist to share, viralizing the response and neutralizing the detected message.
If Cambridge Analytica sought to manipulate you like a little puppet, this app seeks, directly, to turn you into its henchman.
.- Dell Cameron in Wired: the DHS is looking for a centralized biometric search engine centralized that unifies face, fingerprint, iris and more searches across the whole hodgepodge amassed by Homeland Security, replacing a mosaic of isolated systems. Coordinating that mosaic is precisely the problem: the focus is on 1:N identification with adjustable thresholds, where power shifts to the genius who does the “tuning”. And if it’s tuned too loosely, the number of false positives shoots up.
The frictions are substantial: incompatible formats, the need for “bridges” or massive reconversion of biometric templates and scale risks. You can also see the eagerness to incorporate voiceprints in a context of ubiquitous voice cloning. The news isn’t so much “more biometrics”, as the idea of centralizing the matching layer: whoever controls the engine will control auditing, biases, traceability and, de facto, public policy.
.- The true story of LinkedIn’s “verification badge”: Getting verified on LinkedIn implies a broader chain of data sharing than it seems. The post dissects what’s captured (document, selfie/biometrics, device metadata) and how the flow relies on third parties, with effects on purpose, retention and reuse. The author links verification to a pattern: “friction” turned into a signal of reputation, and reputation turned into reach-and-trust gating. It also lands the slippery-function risk: a verification designed to fight fraud ends up acting as reusable identity infrastructure. TL;DR: what’s delicate isn’t only the data handed over today, but the future asymmetry: a platform can change which privileges are tied to the “verified” attribute without real re-consent, pushing users toward mandatory identity by design.
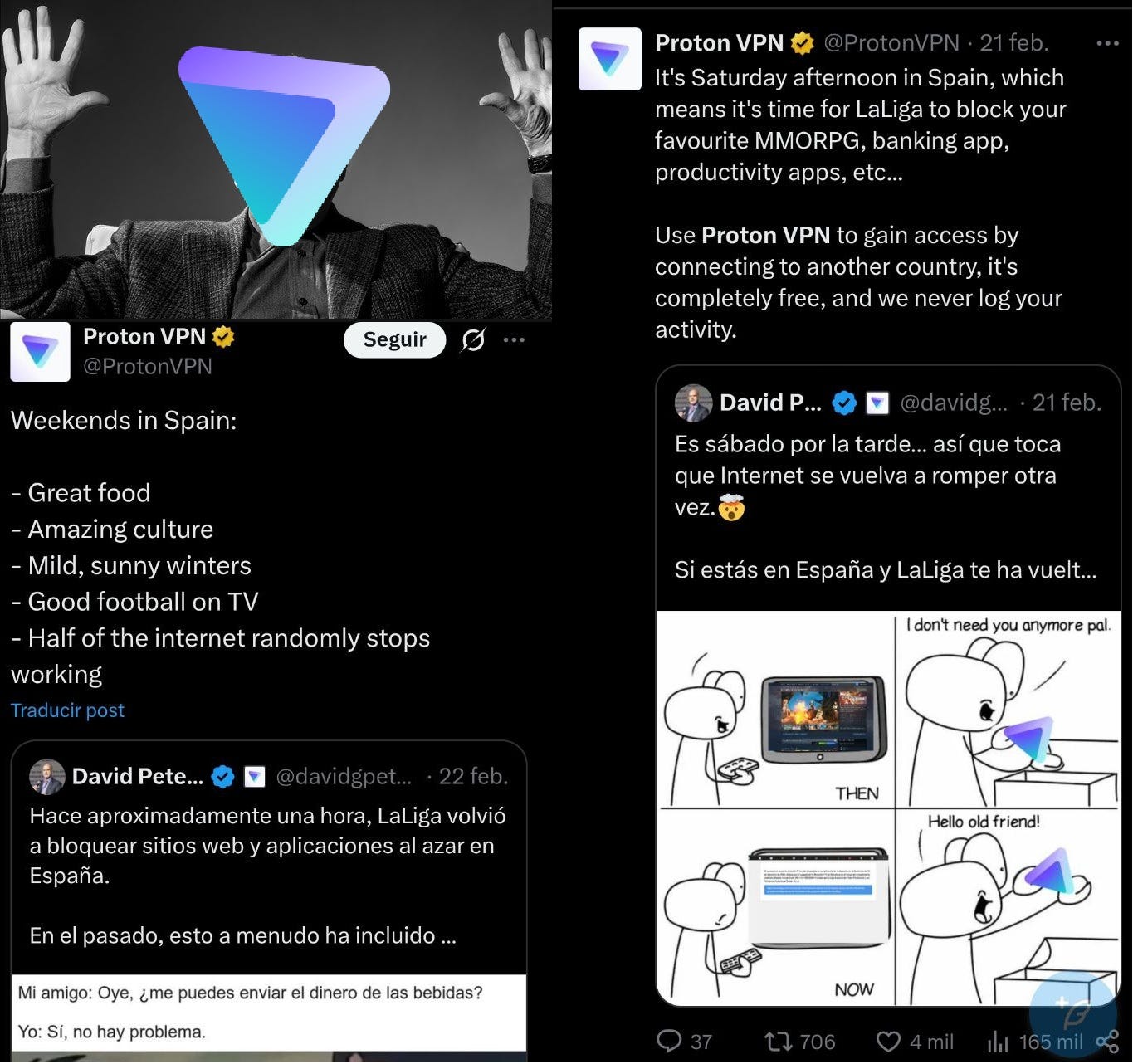
.- Trump vs Tebas.- The debate about VPNs is living a plot twist no one saw coming. In previous episodes of this soap opera, a judge in Córdoba ordered ProtonVPN and NordVPN to disable from their tool the IPs dynamically blocked by LaLiga during matches. The laughter of the Proton gentlemen has been heard all the way from Switzerland.
Our tears reach the Rhône, but that’s not news in “Spain-web” turned into LaLiga’s private estate.
Well, now the U.S. Government bursts in with a website that aims to offer a kind of online VPN service so poor Europeans can bypass the unjust restrictions on our freedom of expression.
We’re not including the link to that website here because, in case it isn’t sufficiently clear, we don’t approve of that measure. Nor the other one. Nor anyone’s this week whose surname starts with “T”.
This is (i) a totemic example of a good-ish action for all the wrong reasons and (ii) a big warning to be very careful whose claws you put your browsing and your data in, because usually the cure is worse than the disease.
.- That very Monday, to start off at full throttle, a EDPS–a gazillion DPAs joint opinion was published (with the Basque and Catalan ones, but without the AEPD ??), about the risks posed by the generative creation of non-consensual intimate images (to be polite), defamatory, or in any way harmful images of a real person. Even if the document is 80% a declarative list of the signing authorities, it’s a clear heads-up to sailors + that they’re going to start coordinating to do something. Like a good public authority document, they don’t clarify what that cooperation will consist of, but it’s understood we’ll have documents on the topic.
They do talk about the importance of controllers applying the strongest possible security measures, transparency about what the system does, acceptable uses and consequences of misuse, having mechanisms for content removal requests by affected people. What they should already have in order to comply with what must be complied with on multiple fronts.

.- Will the RAM crisis affect your privacy? YEP:
Phone and laptop manufacturers (and TVs and Raspberry Pis, etc…) compete with data centers, driving up prices and reshaping product lines. But what interests us here is the “invisible externality” in the privacy context: when memory is scarce and more expensive, we’re pushed into more intense compute “streaming” for local features, shifting data off the device. In other words, RAM can decide whether your AI/analytics lives on the phone… or on someone else’s server.
Remember what happened during lockdown? Well, another aftershock is coming.
.- Reddit gets the new multi-million sanction for violating children’s data protection. That very particular, niche social network that makes certain topics explode.
The thing is, they’ve been hit with a £14.47 million penalty for:
· Not having an effective age verification system that prevented the massive processing of personal data of children under 13 without any lawful basis. The GDPR doesn’t require a verification system, but not having one leads you to non-compliance because you’re processing children’s data without a lawful basis.
· No trace of a PIA on this topic.
The ICO says that in 2025 Reddit put in a self-declarative verification system, but they already told them it’s a formal measure that doesn’t prevent a minor from bypassing it. The classic one we’ve all bypassed at some point.

📄High density docs for data junkies☕️
.- This Q&A doc on data governance by Stefaan Verhulst and Begoña G. Otero is interesting and useful: what it is, what it isn’t, how to define the work’s perimeter and how to communicate objectives to incumbents.
Some nuggets: It perfectly differentiates governance from strategy (the former sets rules; the latter seeks value) and from management (technical operation). And it warns against technological determinism: either you work on governance early or the IT gentlemen will eat you from the feet up—design decisions can become governance de facto if they aren’t explicitly governed.
.- Bridges to Self: Silent Web-to-App Tracking on Mobile via Localhost Do you remember the Meta “Localhost” mess from last summer? This paper with a poetic name has come out by Narseo Vallina-Rodriguez, Gunes Acar, Frederik Zuiderveen Borgesius, Tim Vlummens, Aniketh Girish and Nipuna Weerasekara on the subject.
An Android permissions update has also come out to prevent Zuck from pulling the same bastard move again. You can bet he’ll do others, but not this one.

💀Death by Meme🤣
🤖NoRobots.txt or The AI Stuff
.- Ethan Mollick updates every few months his guide to choosing AI today . The author reframes the dilemma: it’s no longer enough to compare models; you have to separate model, app and “harness” that enables tools, actions and autonomy. He explains why the same model behaves differently depending on its interface and capabilities: manual selection of “thinking” variants, code execution, connectors, and deep research. He also warns about the bias of free models, optimized for conversation and not for accuracy. With specific recommendations for different needs.
A must-read every time it comes out.
.- Yet another paper announcing that it has extracted quasi-literal copies (>95%) of popular books from hegemonic AI models. Extracting books from production language models, by Ahmed Ahmed; A. Feder Cooper; Sanmi Koyejo; Percy Liang.
.- The joke tells itself:
The paper of the week
The political effects of X’s feed algorithm (Nature): A field experiment on X compares algorithmic vs chronological feed for seven weeks with U.S. users, measuring attitudes and online behavior. Switching from the chronological feed to the algorithmic one increases engagement (no surprise there) and shifts opinions toward more conservative positions in politics and perceptions about events. That said, the reverse change doesn’t show comparable effects; nor are there strong changes in affective polarization or self-reported extremism.
The proposed methodology is exposure + follow-up: the algorithm promotes conservative content and devalues traditional media, pushing users to follow activists, and those follows persist. The key is the temporal asymmetry: “turning off” the algorithm may not reverse anything if it already modified your social graph.
Authors: Germain Gauthier; Roland Hodler; Philine Widmer; Ekaterina Zhuravskaya.
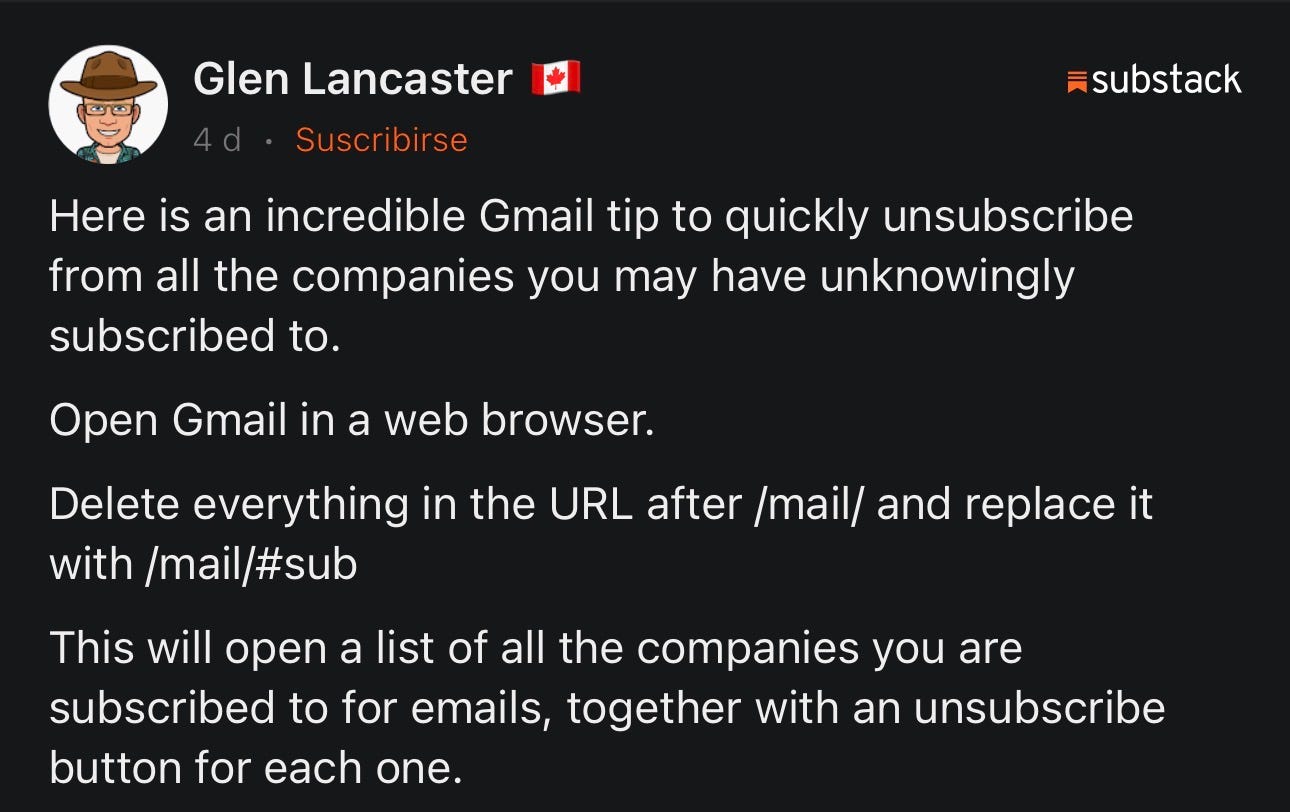
Useful tools
Not useful: super useful. Especially if you still trust Gmail.
And another one: Nearby glasses.

🙄 Da- Tadum Bass!
If you think this newsletter might appeal to and even be useful to someone, forward it to them.
If you miss any doc, comment, or dumb thing that clearly should have been in this week’s Zero Party Data, write to us or leave a comment and we’ll consider it for the next one.