

#49 DeepSeek vuelve
"Nuestro glorioso entrenamiento, su bárbara destilación"
El pasado 23 de febrero, Anthropic denunció que DeepSeek, Moonshot AI y MiniMax habían llevado a cabo “campañas de destilación a escala industrial” contra sus modelos Claude.
¿Qué demonios quiere decir eso de “destilación”?
Se lo explico en un momento, pero antes, un flashback rollo Sofía Petrillo:
“San Francisco, año 2023”. Un ingeniero de Google publica un paper con este jugosón título: “We Have No Moat, And Neither Does OpenAI“.
Lo de “moat” se refiere al “foso competitivo”: la ventaja -normalmente temporal- que permite a una empresa mantener una distancia cómoda sobre sus competidores.
Su tesis: ni Google ni OpenAI tenían una ventaja de esas.
La comunidad open source lograría con 100 dólares lo que a las grandes empresas les costaba 10 millones.
Tres años después, DeepSeek le dio la razón de espectacular manera: se podían obtener resultados competitivos con una fracción del presupuesto. Nunca hubo foso. Peor aún: sigue sin haberlo.
Mediante la destilación de modelos un modelo grande (el “Profe”) transfiere su conocimiento a uno más pequeño (”Mascotilla”). Mascotilla hace millones de preguntas al Profe y registra sus respuestas. Después se usa ese corpus de respuestas para entrenar a Mascotilla, o a un clon: “Mascotilla copión”.
Destilar, en suma, es “abrasar a preguntas a” o “hacerse una chuleta con” los apuntes del gafotas de clase.
Es comprimir inteligencia: obtener un modelo más modesto que se comporte de forma parecida al grande original pero consumiendo una fracción de los recursos.
¿Dónde está la grasia de todo esto?
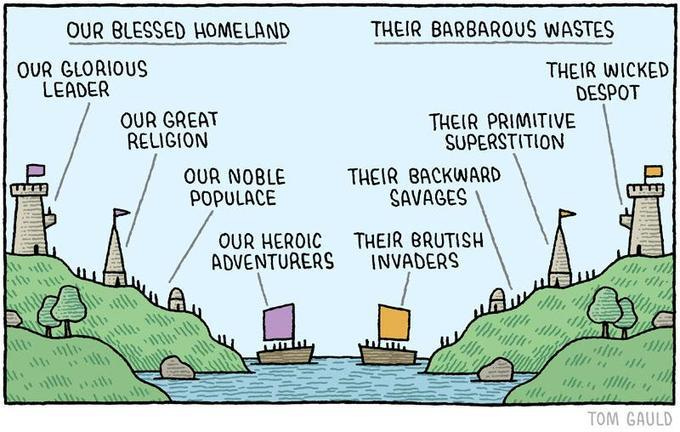
Yo venía a hablar de la gloriosa e irónica viñeta adjunta (creada, para más inri, con ChatGPT seguramente). Recrea una épica, histórica viñeta original de Tom Gauld “Our Blessed Homeland / Their Barbarous Wastes”, publicada en The Guardian en 2015. Un clásico instantáneo que retrata de un plumazo y para siempre el concepto de “disonancia cognitiva”.
Como señala The Register: “Anthropic accuses China’s AI labs of ripping off content — just like it did.“
Según Anthropic, los laboratorios chinos crearon más de 24.000 cuentas fraudulentas y generaron 16 millones de prompts (¡!) para extraer las capacidades de Claude y mejorar sus propios modelos.
Esto se presenta, naturalmente, como una amenaza a la seguridad nacional. Su propio expolio de obras ajenas para entrenamiento de Claude fue un acto de audacia innovadora, más allá del bien y del mal (“our blessed model training”).
Anthropic (y las demás) construyeron su negocio entrenando sus modelos con cantidades ingentes de contenido ajeno: libros, artículos, código, foros, páginas web aspiradas por sus crawlers sin permiso de los autores.
Se amparan en la doctrina del “fair use” y se justifican en la innovación. Pero cuando otros les roban a ellos empleando una lógica similar -extraer conocimiento de un modelo existente para crear otro- el mismo asunto se convierte en “destilación bárbara” y amenaza existencial.

El épico original:
Estás leyendo ZERO PARTY DATA. La newsletter sobre actualidad y derecho tecnológico de Jorge García Herrero y Darío López Rincón.
En los ratos libres que nos deja esta newsletter, resolvemos movidas complicadas relacionadas con la normativa de protección de datos personales e inteligencia artificial. Si tienes de alguna de esas, haznos así con la manita. O contáctanos por correo en jgh(arroba)jorgegarciaherrero.com
🗞️Noticias del Mundodato 🌍
.- Sólo estas dos noticias que hemos leído hoy miércoles, podrían justificar una edición tecnófoba y negrísima, pero ya adelanto que ha salido el sol después de dos meses y todos nos merecemos algo mejor.
La primera noticia.- No estaba ni seca la tinta del titular anunciando que Anthropic se distanciaba del Gobierno USA para evitar la aplicación de su tecnología fuera de las indispensables salvaguardias limitaciones propias de una organización donde la seguridad de la Humanidad es lo primero. Esa es la premisa que explica que los hermanos Amodei y sus compañeros más concienciados abandonaran OpenAI para fundar Anthropic, vaya.
Bueno, pues el plante no ha durado ni una semana. Porque “si la competencia no sigue las mimas premisas morales y de seguridad que tú, mueres inútilmente” dice Darío Amodei.
Esas son palabras acuñadas y repetidas muchas veces por Sam Altman, dice Karen Hao.
La segunda noticia.- Canadá (y pronto, el resto del mundo, no lo duden) vivirá la puesta de largo de una grasiosa app israelí cuya funcionalidad es convertir al ciudadano de a pie en arma arrojadiza del partido político con el que simpatiza. La app se llama Victory app y está desarrollada por LogiVote. Una vez instalada en el móvil del militante, aspira sus contactos, escanea las redes sociales instaladas, detecta mensajes contrarios al candidato promovido y (ojo a esto) genera contranarrativas en tiempo real para que el militante las comparta, viralizando la respuesta y neutralizando el mensaje detectado.
Si Cambridge Analytica buscaba manipularte como a un muñequito, esta app busca, directamente, convertirte en su esbirro.
.- Dell Cameron en Wired: el DHS busca un buscador biométrico centralizado que unifique las búsquedas de rostro, huella, iris y más entre todo el batiburrillo amasado por la Homeland Security, sustituyendo un mosaico de sistemas aislados. La coordinación de ese mosaico es precisamente el problema: el foco está en la identificación 1:N con umbrales ajustables, donde el poder se traslada al genio que hace el “ajuste”. Y si queda poco ajustado, se dispara el número de falsos positivos.
Las fricciones son sustanciales: formatos incompatibles, necesidad de “puentes” o reconversión masiva de plantillas biométricas y riesgos de escala. También se aprecian las ganazas de incorporar voiceprints en un contexto de clonación ubicua de voz. La noticia no es tanto “más biometría”, como la ideaca de centralizar la capa de matching: y es que quien controle el motor controlará la auditoría, sesgos, trazabilidad y, de facto, la política pública.
.- La verdadera historia de la “verification badge” de Linkedin: Verificarte en LinkedIn implica una cadena de cesiones de datos más amplia de lo que parece. El post disecciona qué se captura (documento, selfie/biometría, metadatos del dispositivo) y cómo el flujo se apoya en terceros, con efectos en finalidad, retención y reutilización. El autor conecta la verificación con un patrón: “fricción” convertida en señal de reputación, y reputación convertida en gating de alcance y confianza. También aterriza el riesgo de función deslizante: una verificación pensada para combatir fraude termina actuando como infraestructura de identidad reutilizable. ENO: lo delicado no es solo el dato entregado hoy, sino la asimetría futura: una plataforma puede cambiar qué privilegios se atan al atributo “verificado” sin re-consentimiento real, empujando a usuarios a una identidad obligatoria por diseño.
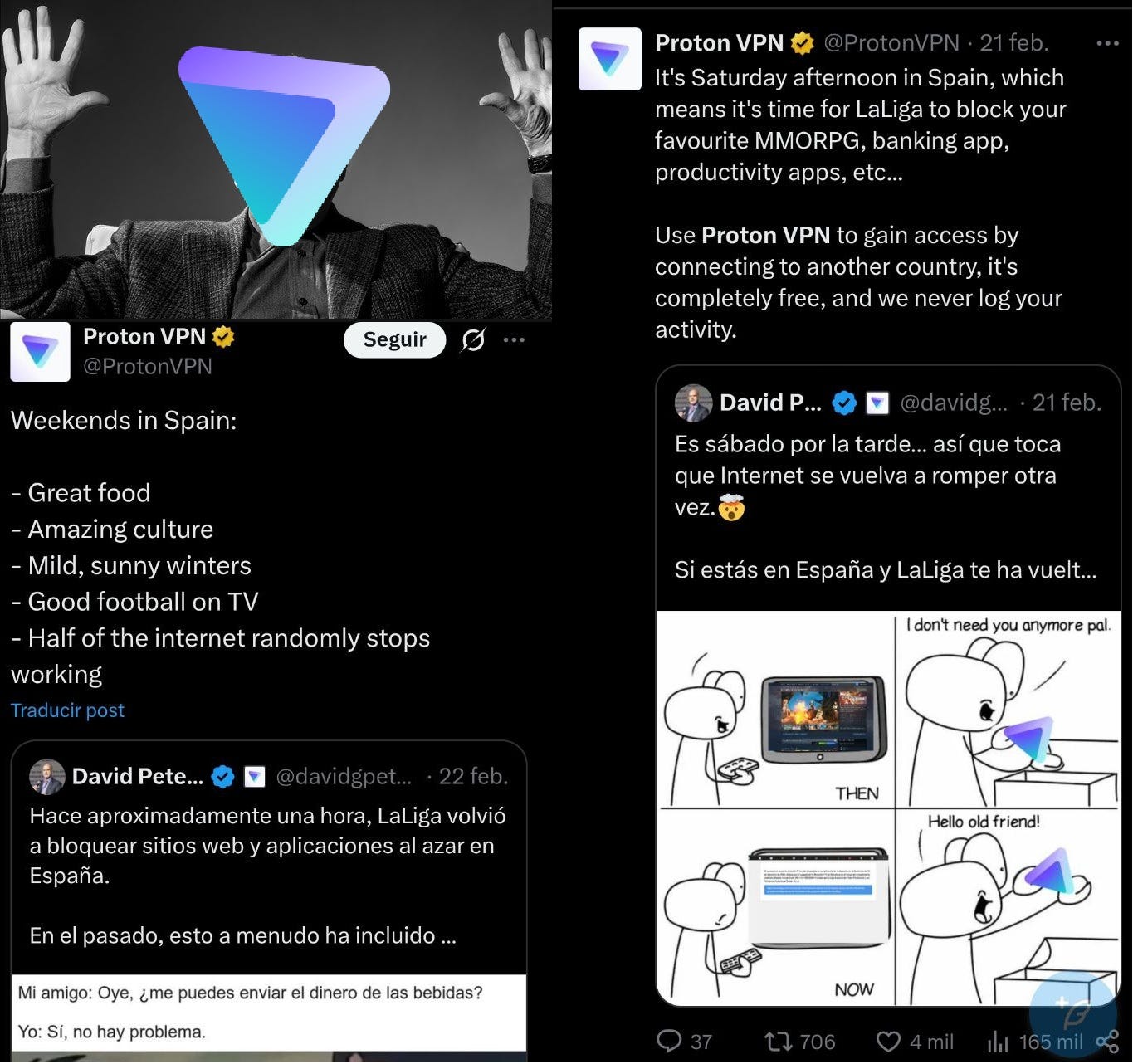
.- Trump contra Tebas.- El debate sobre VPNs vive un plot twist que nadie vio venir. En episodios anteriores de este culebrón, un juez de Córdoba ha ordenado a ProtonVPN y NordVPN que desactiven de su utilidad las IPs bloqueadas de forma dinámica por LaLiga durante los partidos. Las carcajadas de los señores de Proton se han oído desde Suiza.
Nuestras lágrimas llegan al Ródano, pero eso no es noticia en la Españita-web convertida en el cortijo de LaLiga.
Pues bien, ahora el Gobierno de EE. UU. irrumpe con una web que pretende ofrecer un especie de servicio de VPN online para que los pobresitos europeos sorteen las injustas restricciones a nuestra libertad de expresión.
No incluimos aquí el enlace a esa web porque, por si no queda suficientemente claro, no aprobamos esa medida. Ni la otra. Ni la de nadie cuyo apellido empiece por “T” esta semana.
Esto es (i) un ejemplo totémico de acción favorable por las razones equivocadas y de (ii) mucho cuidado de en qué zarpas pones tu navegación y tus datos porque normalmente es peor el remedio que la enfermedad.
.- El mismito lunes para empezar a tope, se publicó un dictamen conjunto EDPS- tropecientas DPAs (con la vasca y catalana, pero sin la AEPD ¿?), sobre las riesgos que tiene la creación generativa de imágenes no consentidas de índole íntima (por ser finos), difamatorias o de cualquier forma dañinas de una persona real. Aunque el documento sea un 80% listado declarativo de las autoridades firmantes, es un claro aviso a navegantes + que van a empezar a coordinarse para hacer algo. Como buen documento de autoridades públicas, no aclaran en qué va a consistir esa cooperación, pero se entiende que tendremos documentos sobre el tema.
Sí hablan de la importancia de que los responsables apliquen medidas de seguridad lo más sólidas posibles, transparencia sobre lo que haga el sistema, usos aceptables y consecuencias de un uso indebido, tenga mecanismos de solicitud de eliminación de contenido por las personas afectadas. Lo que ya deberían tener para cumplir con la que se debe cumplir con varios frentes.

.- ¿La crisis de RAM afectará a tu privacidad? SIP:
Los fabricantes de móviles y portátiles (y TVs y Raspberri Pis, etc…) compiten con centros de datos, elevando precios y reconfigurando gamas. Pero lo que nos interesa aquí es la “externalidad invisible” en el contexto de privacidad: cuando la memoria es escasa y más cara, se nos empuja a un “streaming” más intenso de cómputo para funciones locales, desplazando datos fuera del dispositivo. En otras palabras, la RAM puede decidir si tu IA/analítica vive en el móvil… o en un servidor ajeno.
Recuerdan lo que pasó en el confinamiento? Pues viene otra réplica de aquel terremoto.
.- Reddit se lleva la nueva sanción millonaria por vulnerar la protección de datos de los menores. Esa red social tan particular y de nicho que hace que determinados temas exploten.
El caso es que se han llevado una sanción de 14,47 millones de libras por:
· No disponer de un sistema efectivo de verificación de edad, que evitara el tratamiento masivo de datos personales de menores de 13 años sin base de legitimación alguna. El RGPD no obliga a un sistema de verificación, pero el no tenerlo te lleva al incumplimiento por estar tratando datos de menores sin legitimación.
· Ni rastro de PIA sobre este tema.
El ICO habla de que en 2025 Reddit metió un sistema de verificación autodeclarativo, pero que ya les dijeron que es medida formal que no impide que el menor lo puentee. El típico de toda la vida que todos hemos puenteado en algún momento.

📖 Documentos dateros muy cafeteros ☕️
.- Este doc de Q&A sobre data governance de Stefaan Verhulst y Begoña G. Otero es interesante y útil: qué es, qué no es, cómo delimitar el perímetro del trabajo y cómo comunicar los objetivos a incumbentes.
Algunos nuggets: Diferencia perfectamente gobernanza de estrategia (la primera fija reglas; la segunda busca valor) y de gestión (operación técnica). Y advierte contra el determinismo tecnológico: o trabajas la gobernanza temprano o los caballeretes de IT te comerán por los pies: las decisiones de diseño pueden volverse gobernanza de facto si no se gobiernan explícitamente.
.- Bridges to Self: Silent Web-to-App Tracking on Mobile via Localhost ¿Se acuerdan de la movida del “Localhost” de Meta del verano pasado? Ha salido este paper de poético nombre de Narseo Vallina-Rodriguez, Gunes Acar, Frederik Zuiderveen Borgesius, Tim Vlummens, Aniketh Girish y Nipuna Weerasekara sobre el tema.
También ha salido una actualización de permisos en android para evitar que Zuck vuelva a hacer la misma cabronada. Pueden apostar a que hará otras, pero ésta ya no.

💀Death by Meme🤣
🤖NoRobots.txt o Lo de la IA
.- Ethan Mollick actualiza cada pocos meses su guía para elegir IA hoy. El autor redefine el dilema: ya no basta comparar modelos; hay que separar modelo, app e “harness” (arnés) que habilita herramientas, acciones y autonomía. Explica por qué el mismo modelo se comporta distinto según su interfaz y capacidades: selección manual de variantes “thinking”, ejecución de código, conectores, y deep research. También advierte sobre el sesgo de los modelos gratuitos, optimizados para conversación y no para precisión. Con recomendaciones específicas para distintas necesidades.
Un must read cada vez que sale.
.- Otro paper más anunciando haber extrado copias cuasiliterales (>95%) de libros populares de modelos hegemonicos de IA. Extracting books from production language models, de Ahmed Ahmed; A. Feder Cooper; Sanmi Koyejo; Percy Liang.
.- El chiste se cuenta solo:
El paper de la semana
The political effects of X’s feed algorithm (Nature): Un experimento de campo en X compara feed algorítmico vs cronológico durante siete semanas con usuarios de EE. UU., midiendo actitudes y conducta online. Pasarse del feed cronológico al algorítmico aumenta el engagement (nada sorprendente hasta aquí) y desplaza opiniones hacia posiciones más conservadoras en política y percepción sobre eventos. Dicho esto, el cambio inverso no muestra efectos comparables; tampoco hay cambios fuertes en polarización afectiva o extremismo autodeclarado.
La metodología propuesta es de exposición y seguimiento: el algoritmo promueve contenido conservador y devalúa medios tradicionales, empujando a seguir activistas, y esos follows persisten. La clave es la asimetría temporal: “apagar” el algoritmo puede no revertir nada si ya modificó tu grafo social.
Autores: Germain Gauthier; Roland Hodler; Philine Widmer; Ekaterina Zhuravskaya.
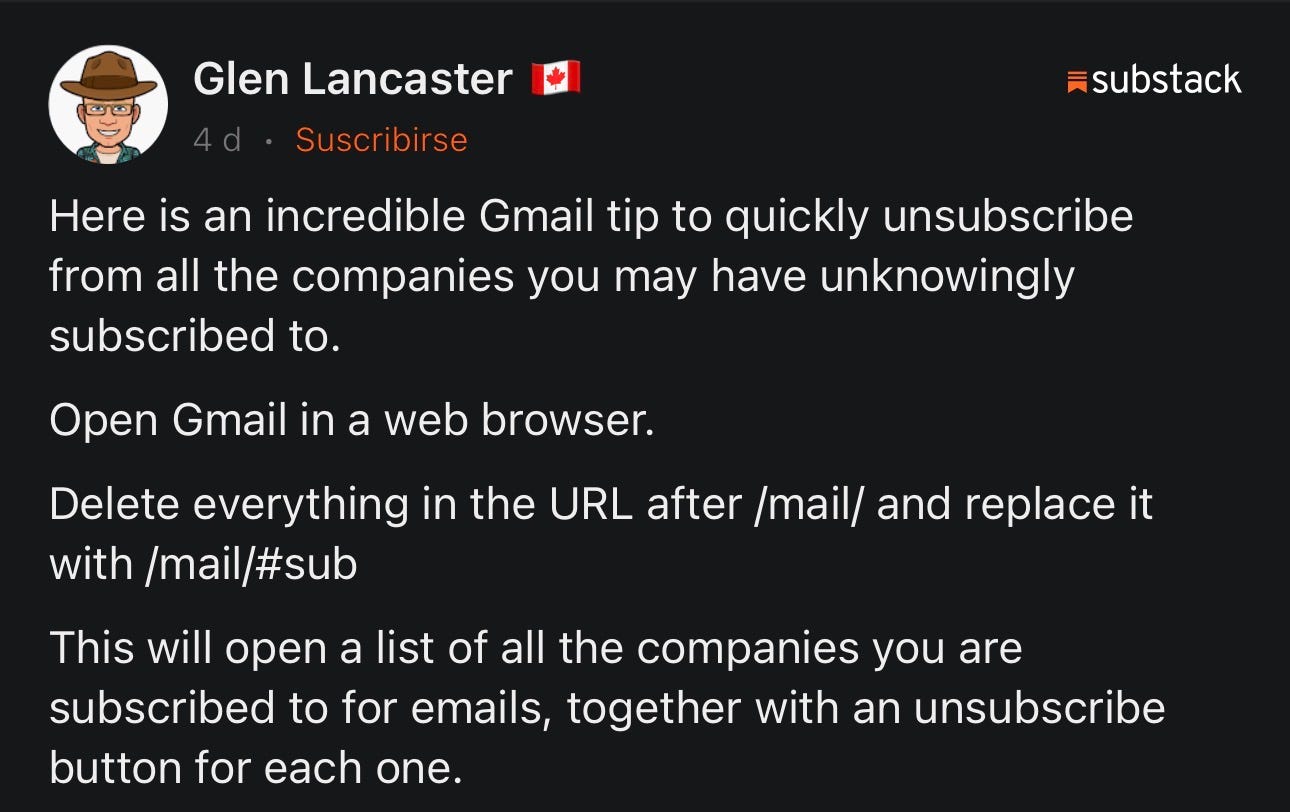
Herramientas útiles
Útil no: utilísimo. En especial si sigues confiando en Gmail.
Y esta otra: Nearby glasses.

🙄 El chorradón final
Si crees que esta newsletter puede gustar e incluso ser útil a alguien, reenvíasela.
Si echas de menos algun doc, comentario o chorradón que manifiestamente debería haber estado en el Zero Party Data de la semana, escríbenos o deja un comentario y lo valoraremos para la próxima.