

Ubiquity
We are suffering a tsunami of rock-bottom-quality content generated by AI: a wave that threatens to flood every corner of our digital life.
We are no longer talking about “tralarero tralará”-type nonsense and cartoons of talking toilets consumed exclusively by teens on YouTube and TikTok.
We are not talking about the shrimp Christ and all those supposedly dodgy news items that only extreme boomers and grandparents (as hooked as the teens) swallow.
I do not even want to start talking about the deserts of self-cloning mediocrity that LinkedIn and Twitter are today.
We are talking about an absolute majority in the elections of the modern connected world. Everyone, absolutely everyone, consumes synthetic garbage with uneven enthusiasm. But we all do it.
“It is good enough for me if it manages to suspend the scrolling little finger of my peers”.
What is AI slop?
The term “slop” —which we could translate as “filth”, “trash” or “that viscous thing nobody wants to touch but that today makes up 75% of the internet”— describes with surgical precision those mediocre texts, images identical to each other but so different from reality, and soulless videos that generative tools mass-produce for pennies.
AI slop is the strawberry flavor of chewing gum.
Any resemblance to the original fruit is pure coincidence.
In an economy that seeks attention at any price, the goal is reduced to identifying your sensitive spot and hitting it with different versions of the same thing until numbness, but without providing any real pleasure or learning in the process.
Perhaps we are living through the AI version of the tragedy of the commons: nobody has incentives to produce content of minimum quality because generating daily tons of slop does the job. For now.
It is AI, but at least Ingarose did not lie about its synthetic condition. As Forbes documented with that tone halfway between astonished and resigned that characterizes contemporary journalism, millions of people paid real money to listen to something no human being felt the need to sing and communicate (until recently, this was the thing about music).
“It is good enough for me if it was good enough to accompany videos on TikTok.”
Art
At some point we will start seeing works that dignify audiovisual AI as a tool for things that are worthwhile, have no doubt. But if you thought (like me, naive me) that this moment of dignification would arrive this year at Cannes with Steven Soderbergh’s film about John Lennon and Yoko Ono, that is going to be a no.
“Authority”
The president of the Canary Islands community provided a chat with ChatGPT as scientific evidence in a socially and politically relevant debate about hantavirus and rodentss.
And he did not climb down from the donkey.
Allow me to repeat this because it deserves to be savored: a democratically elected representative, presumably advised by experts with real academic credentials, decided that the best way to support his reluctance was… to use the source of information his voters use. Ask a chatbot.
“It is good enough for me if a sufficient number of my voters take it as good”.
The anecdote is terrifying, but electorally it surely “does the job”.
Another matter is that in these things it is more interesting to get it right than to gather support.
Medium: from disinformation to marketing
AI, moreover, not content with impacting your life by saturating it with shitty content, spreads to other markets the manipulations that yesterday focused on issues such as political hate messages or disinformation campaigns.
The algorithmic persuasion techniques that used to be reserved for serious things —like manipulating democratic elections or promoting genocides— now, with a portfolio of successful use cases under their arm, extend to more banal but, of course, much more lucrative matters.
It has been discovered that a company called Chaotic Good Projects was doing astroturfing to promote emerging groups and singers.
Chaotic Good Projects created fake profiles on social networks, generated synthetic reviews, manufactured organic conversations about nonexistent or unknown artists, and simulated communities of enthusiastic fans where there was no one real.
Astroturfing —that practice with the name of artificial grass that consists of simulating grassroots movements when in reality they are campaigns orchestrated from above— has found its manna in generative AI.
Creating thousands of convincing accounts, each with its own browsing history, unique writing style, differentiated behavior patterns, and slightly discrepant opinions to seem more authentic, is today technically trivial and dirt cheap.
“It is good enough for me if it lets me replace the wages of one hundred NPCs with a worked-up prompt”.
Before, the radio formula worked as a means of music promotion (and the repetition of ads in the press and TV) and influenced us by crushing us: you heard the same song twenty times a day until you liked it, or at least until you bought it out of pure Stockholm syndrome.
It was transparent manipulation, even shameless, but at least it was done openly. Radio did not pretend to be your friend; it was openly a commercial loudspeaker. There was honesty in shamelessness.
This other thing is much murkier: the influence comes disguised as an organic recommendation, a casual discovery, an emerging trend that “is succeeding among people like you”. Now it is your “community” —fake, nonexistent— apparently recommending things. It is your “friends” who recommend that artist, your “bubble” that validates that decision. Except none of them exists.
But hey, at least you have friends. Or so you think.
Freedom according to Dan Ariely
To what extent are we as free as we think when choosing the product we buy or the music we listen to?
This question is not new, nor do I intend to come and answer it today.
I would be naive if I thought that, by recommending Dan Ariely’s “Predictably Irrational” or at least his TedTalk on the subject (or its transcript and there is no lower barrier anymore), you would give a damn and check any of these resources.
Statistically speaking, 98% of the readers of this paragraph will not click any link, will not read the book, and will continue with their day firmly believing that their decisions are the product of rational deliberation and free will.
Which, ironically, will validate Ariely’s thesis on friction in decision-making.
But allow me to try anyway, because optimism is the last thing to be lost (right before the hair).
At least listen to the talk: the ending is glorious and you will not forget it. Ariely is an MIT expert in economics and applied psychology, one of those academics who devoted decades to experimentally proving that everything you believed about yourself is a lie, and he shows how context, the presentation framework, decoy options and dozens of cognitive biases determine our choices in a predictable and systematic way.
We are not rational agents evaluating information objectively but primates with 200,000-year-old brains navigating environments for which evolution has not prepared us. Our brain developed shortcuts to survive in the African savanna —where quick decisions about which fruit to eat or which predator to flee from were worth more than exhaustive analysis— but those same shortcuts leave us naked before any system designed to exploit our biases.
And almost all of them are.
“I am aware that my choice is not free, but it is good enough for me, if at least it does not brutalize me.”

You are reading ZERO PARTY DATA. The newsletter about tech and legal affairs by Jorge García Herrero and Darío López Rincón.
In the free time that this newsletter leaves us, we solve complicated issues related to personal data protection regulations and artificial intelligence. If you have any of those, give us a hand. Or contact us by email at jgh(at)jorgegarciaherrero.com
🗞️News from the Data World🌍
.- We continue paying attention to the legal AI dialectic against specialized tools with this long post by Sean A. Harrington: on the competitive barriers that hinder the generalization of legal AI.
The structural barriers prevent AI from transforming legal practice, despite 79% of lawyers saying they use AI. Sean Harrington analyzes five main obstacles:
(i) the competitive moat of access to structured and complete databases (only Westlaw, Lexis and vLex/Fastcase possess complete legal databases in the USA, although open-source alternatives like CourtListener and Harvard’s Caselaw Access Project erode that advantage);
(ii the internal organizational disorder in each firm (THIS IS THE FUNDAMENTAL ONE, BABY BOY) (data fragmented across incompatible systems, partnership governance that gives each partner veto power, lack of technological leadership in mid-sized firms);
(iii) the efficiency paradox (billing by the hour discourages automation, although fixed-fee models like ADVOS Legal and Hello Divorce capture the efficiency gains in what I call the “niche nobody wants”);
(iv) supervision risks (Danielle Benecke’s “supervision gap”: when agentic systems handle complete workflows, total human review becomes economically irrational) (we already commented on this here) ; and
(v) the access-to-justice gap (86% of civil legal problems of low-income Americans receive no adequate help).
Especially sad is the case of Microsoft Copilot, designed as the assistant that would help lawyers where they work: in Word: it was rated as “minimally useful for legal work” by Clear Guidance Partners consultants after a year of testing in multiple firms. Microsoft had only 8 million active Copilot users out of 440 million M365 subscribers in August 2025, a conversion rate of 1.8%, revealing the failure of the enterprise software vendor best positioned to sell AI tools to its existing customer base.
.- LinkedIn silently scans installed extensions in your Chrome-based browser and links them to your verified professional identity. Every time a professional accesses LinkedIn via Chrome, Edge, Brave or Opera, hidden JavaScript scans up to 6,278 installed extensions, encrypts the results and transmits them to LinkedIn’s servers, where they are associated with the user’s real name, company and professional history. The system, which has never been disclosed in its privacy policy, is the subject of two federal class-action lawsuits in the United States and a complaint before the European Commission. The list includes 509 job-search tools (1.4 million combined users), religious extensions, accessibility tools that reveal disabilities, political readers and more than 200 direct competitors of LinkedIn products.
The scale of the scan increased from 38 extensions in 2017 to more than 6,000 in February 2026, an increase of 1,252% in two years. LinkedIn justifies the practice as an anti-fraud tool against scraping, but independent researchers found extensions on the list for scheduling Amazon deliveries, pharmacy tools and image downloaders, with no plausible connection to LinkedIn’s alleged justification.

.- The same professionals who in 2023 went on strike to protect themselves from AI now train the AIs that compete with them. You may have read about workers doing Reinforced learning tasks in Congo or Venezuela, but the thing is reaching the developed world much faster than we thought.
A very interesting chronicle by Ruth Fowler in Wired: A Hollywood writer trains AI to pay the rent. Ruth Fowler, screenwriter and showrunner, recounts in the first person how for eight months she completed twenty AI training contracts on five different platforms (Mercor, Outlier, Turing), carrying out annotation tasks, chatbot evaluation and “red-teaming” of dangerous outputs.
The promise of flexibility and high rates runs up against the reality of chaotic onboarding, project cancellations without notice, instantly revoked access and tasks that disappear before they can be completed. **If you allow me another prophecy worthy of the most pessimistic Cassandra: if there is a judicial practice of the future, it is the defense of platform employees: **the training-data supply chain swallows highly qualified workers subjected to precarious conditions that until now we associated with things like Glovo and Uber.
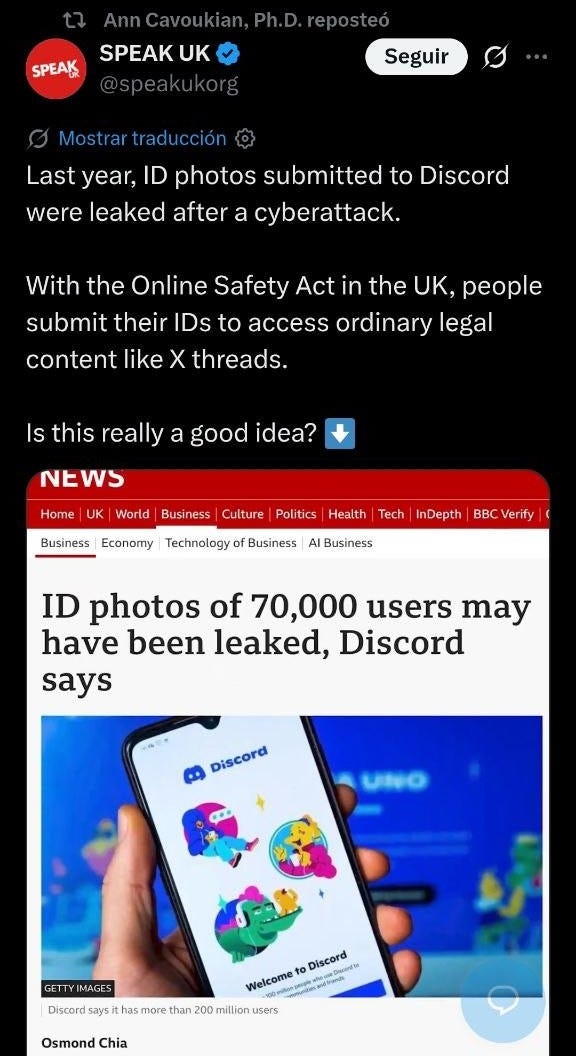
.- We complain on the EU side about how Discord and the rest are doing on the issue of age verification, but on the UK side it is in full fun with flags. The funny thing is that the warnings about the risk of impersonation and worse from going around handing over ID/Passport/identity card predate its leaving the club (for example, the EDPB breach example guidelines). That ordinary personal data that ended up being sensitive without being of a “special category”. Here is added the weight that Cavoukian herself carries it on X.
📖Hard data docs for coffeine lovers☕️
.- The ICO has updated its guidelines on processing children’s data, under its very particular Data (Use and Access) Act (DUAA). Although they are no longer in the club, they continue saying things to take into account. We highlight the following two screenshots on consent and totally automated decision-making with “fun” effects


💀Death by Meme🤣
🤖NoRobots.txt or The AI Stuff
Another week with draft guidelines from the European Commission. Now in the form of a draft on high-risk AI systems, open for public consultation until June 20. The draft of the guidelines and of the two high-risk AI annexes: a matryoshka of three dolls.
Among other things,
The extension of the adaptation margin:
The provision further provides that providers and deployers of high-risk AI systems intended to be used by public authorities shall, in any event, take the necessary steps to comply with the requirements and obligations for high-risk
AI systems by 2 August 2030. Article 111(1) AI Act provides a special regime for AI systems that are components of the large-scale IT systems established by the legal acts listed in Annex X AI Act which have been placed on the market or put into service before 2 August 2027. Those systems should be brought into compliance with the high-risk requirements of the AI Act by 31 December 2030
That a general-purpose system may come to be considered high-risk by default, if in all the documentation (instructions for use, contract, policies, sales materials and technical documentation) the provider does not clarify and apply limitations for said high-risk use variable
In matching fashion, that the distributor, importer or deployer who substantially modifies the system or changes its intended purpose toward high risk will end up being declared a provider.
Much better explained what this draft guidelines contains, in the following video by Robert Bateman.
🛠️Useful tools
.- Damien Charlotin maintains the database of the most complete data on AI hallucination cases in global judicial practice, with 1,455 cases identified to date, tracking court decisions from courts around the world in which it was established that a party relied on content hallucinated by generative AI, typically fake citations but also other AI-generated arguments. The database is searchable by country, party, AI tool and judicial outcome. The cases range from Argentina to Zimbabwe, with the United States representing 1,004 cases, followed by Canada (152), Australia (74) and Israel (52). 86% of the cases involved pro se litigants, while 554 cases involved lawyers.
.- The Irish Council for Civil Liberties has released Verity MCP, an open-source tool that minimizes hallucinations emitted by LLMs through seven layers of verification: strict citation rules, LLMs from different families, natural language inference (NLI), deterministic arithmetic recomputation, consistency sampling, perplexity analysis and dispute resolution among critics. It works on modest hardware (a 2019 GPU as secondary) and integrates with LM Studio.
Verity produces simultaneous second opinions using a secondary GPU while the primary model responds, allowing both responses to be evaluated.
🙄 Da-Tadum-bass
.
If you miss any doc, comment, or dumb thing that clearly should have been in this week’s Zero Party Data, write to us or leave a comment and we’ll consider it for the next one.