

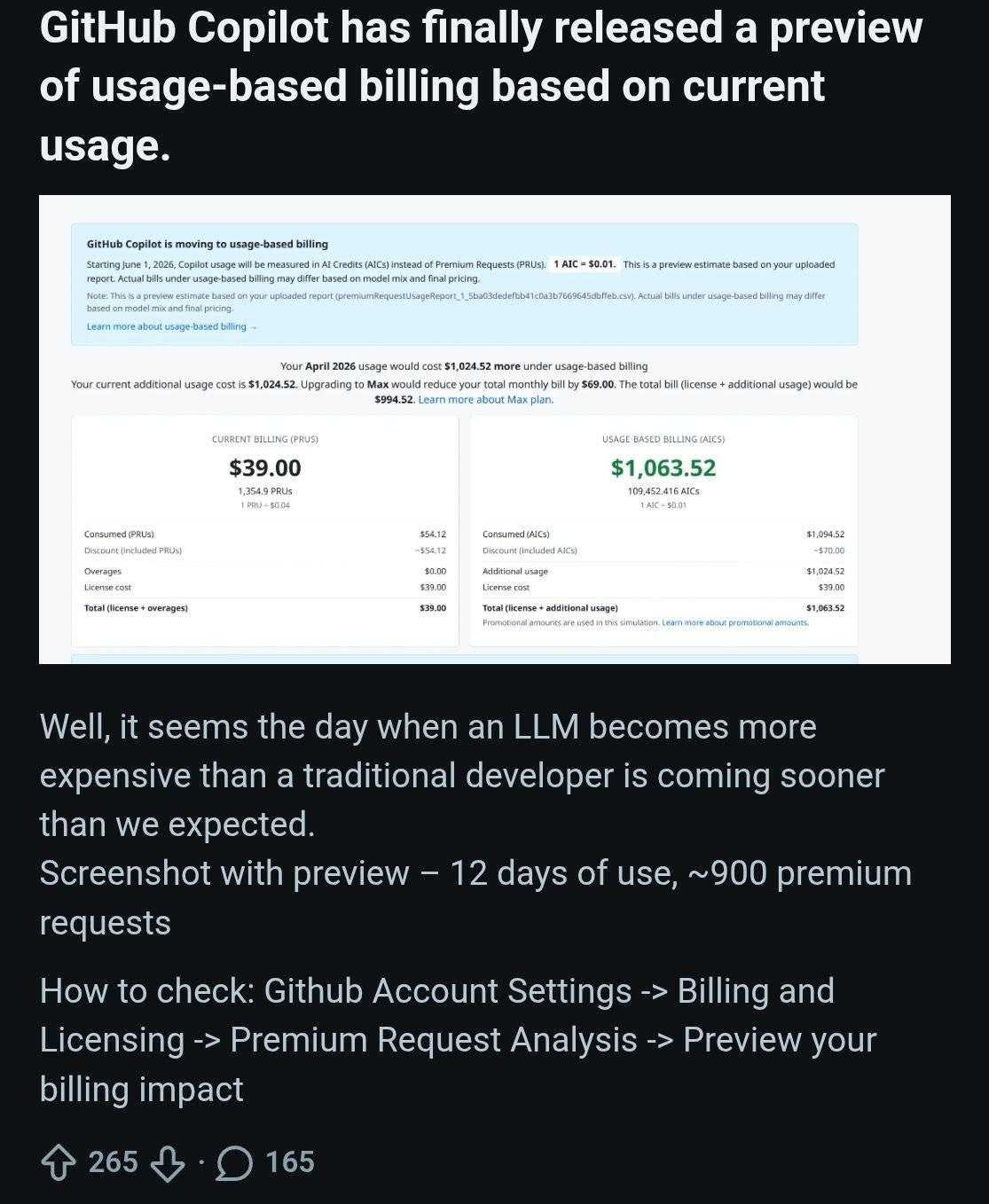
#60 AI slop por todas partes
Slop, sloppity slop
Ubicuidad
Sufrimos un tsunami de contenidos de ínfima calidad generados por IA: una ola que amenaza con inundar cada rincón de nuestra vida digital.
Ya no hablamos de chorradas tipo “tralarero tralará” y dibus de inodoros parlantes de exclusivo consumo teen en Youtube y TikTok (tralarero tralará).
No hablamos del cristo de las gambas y todas esas supuestas noticias chungas que sólo los boomers extremos y los abuelos (tan enganchados como los teens) se tragan.
No quiero ni empezar a hablar de los desiertos de mediocridad que se clona a sí misma que son hoy Linkedin y Twitter.
Hablamos de una mayoría absoluta en las elecciones del moderno mundo conectado. Todos, absolutamente todos, consumimos basura sintética con desigual entusiasmo. Pero todos lo hacemos.
“Es suficientemente bueno para mí si consigue suspender el dedito escrolero de mis pares”.
¿Qué es AI slop?
El término “slop” -que podríamos traducir como “bazofia”, “bodrio” o “esa cosa viscosa que nadie quiere tocar pero que integra hoy el 75% de internet”- describe con precisión quirúrgica esos textos mediocres, imágenes iguales entre sí, pero tan distintas a lo real, y vídeos sin alma que las herramientas generativas producen en masa por dos duros.
El AI slop es el sabor fresa de los chicles.
Cualquier parecido con el de la fruta original es pura coincidencia.
En una economía que busca la atención a cualquier precio, el objetivo se reduce a identificar tu punto sensible y golpearlo con distintas versiones de lo mismo hasta el entumecimiento, pero sin proporcionar placer o aprendizaje real alguno en el proceso.
Quizá estemos viviendo la versión IA de la tragedia de los comunes: nadie tiene incentivos para producir contenido de una calidad mínima porque generar toneladas diarias de slop cumple la papeleta. De momento.
Es IA, pero al menos Ingarose no mentía sobre su condición sintética. Como documentó Forbes con ese tono entre asombrado y resignado que caracteriza al periodismo contemporáneo, millones de personas pagaron dinero real por escuchar algo que ningún ser humano sintió la necesidad de cantar y comunicar (ésta era hasta hace poco la cosa de la música).
“Es suficientemente bueno para mí si lo era para acompañar vídeos en TikTok.”
Arte
En algún momento empezaremos a ver obras que dignifiquen a la IA audiovisual como herramienta para cosas que merezcan la pena, no lo duden. Pero si pensaban (como yo, ingenuo de mí) que ese momento de dignificación llegaría este año en Cannes con la película de Steven Soderbergh sobre John Lennon y Yoko Ono, va a ser que no.
“Autoridad”
El presidente de la comunidad canaria aportaba un chat con ChatGPT como evidencia científica en un debate social y políticamente relevante sobre hantavirus y roedoreh.
Y no se bajó de la burra.
Permítanme repetir esto porque merece ser saboreado: un representante electo democráticamente, presumiblemente asesorado por expertos con credenciales académicas reales, decidió que la mejor forma de dar soporte a sus reticencias era… utilizar la fuente de información que utilizan sus votantes. Preguntarle a un chatbot.
“Es suficientemente bueno para mí si un número suficiente de mis votantes lo da por bueno”.
La anécdota acojona, pero electoralmente “cumple” fijo.
Otra cosa es que en estas cosas interese acertar, más que concitar adhesiones.
Medio: de la desinformación al marketing
La IA, además, no contenta con impactar en tu vida saturándola de contenido mierdoso, contagia a otros mercados las manipulaciones que ayer se centraban en cuestiones como los mensajes políticos de odio o las campañas de desinformación.
Las técnicas de persuasión algorítmica que antes se reservaban para cosas serias -como manipular elecciones democráticas o promover genocidios- ahora, con un porfolio de casos de uso exitosos bajo el brazo, se extienden a cuestiones más banales pero claro, mucho más lucrativas.
Se ha descubierto que una empresa llamada Chaotic Good Projects hacía astroturfing para la promoción de grupos y cantantes emergentes.
Chaotic Good Projects creaba perfiles falsos en redes sociales, generaba reseñas sintéticas, fabricaba conversaciones orgánicas sobre artistas inexistentes o desconocidos, y simulaba comunidades de fans entusiastas donde no había nadie real.
El astroturfing —esa práctica con nombre de césped artificial que consiste en simular movimientos de base cuando en realidad son campañas orquestadas desde arriba— ha encontrado en la IA generativa su maná.
Crear miles de cuentas convincentes, cada una con su propio historial de navegación, estilo de escritura única, patrones de comportamiento diferenciados, y opiniones ligeramente discrepantes para parecer más auténticas, resulta hoy técnicamente trivial y tirado de precio.
“Es suficientemente bueno para mí si me permite sustituir los sueldos de cien NPCs por un prompt currao”.
Antes funcionaba la radiofórmula como medio de promoción musical (y la reiteración de anuncios en prensa y tv) y nos influía por aplastamiento: escuchabas la misma canción veinte veces al día hasta que te gustaba, o al menos hasta que la comprabas por puro síndrome de Estocolmo.
Era manipulación transparente, descarada incluso, pero al menos se hacía a cara descubierta. La radio no fingía ser tu amigo; era abiertamente un altavoz comercial. Había honestidad en la desvergüenza.
Esto otro es mucho más turbio: la influencia viene disfrazada de recomendación orgánica, de descubrimiento casual, de tendencia emergente que “está triunfando entre gente como tú”. Ahora es tu “comunidad” -falsa, inexistente- aparentemente recomendando cosas. Son tus “amigos” los que recomiendan ese artista, tu “burbuja” la que valida esa decisión. Excepto que ninguno de ellos existe.
Pero hey, al menos tienes amigos. O eso crees.
La libertad según Dan Ariely
Hasta qué punto somos tan libres como creemos al elegir el producto que compramos o la música que escuchamos?
Esta pregunta no es nueva, ni pretendo venir yo a contestarla hoy.
Yo sería un iluso si pensara que, recomendándoles “Predictably Irrational” de Dan Ariely o al menos su TedTalk sobre el tema (o su transcripción y ya no hay barrera más baja), ustedes harían puto caso y chequearían alguno de estos recursos.
Estadísticamente hablando, el 98% de los lectores de este párrafo no clickarán ningún enlace, no leerán el libro, y continuarán con su día creyendo firmemente que sus decisiones son producto de deliberación racional y libre albedrío.
Lo cual, irónicamente, validará la tesis de Ariely sobre fricción en la toma de decisiones.
Pero permítanme intentarlo de todas formas, porque el optimismo es lo último que se pierde (justo antes del pelo).
Escuchen al menos la charla: el final es glorioso y no lo olvidarán. Ariely, es un experto del MIT en economía y psicología aplicada, uno de esos académicos que dedicó décadas a demostrar experimentalmente que todo lo que creías sobre ti mismo es mentira, muestra cómo el contexto, el marco de presentación, las opciones-señuelo y decenas de sesgos cognitivos determinan nuestras elecciones de forma predecible y sistemática.
No somos agentes racionales evaluando información objetivamente sino primates con cerebros de 200.000 años de antigüedad navegando entornos para los que la evolución no nos ha preparado. Nuestro cerebro desarrolló atajos para sobrevivir en la sabana africana —donde las decisiones rápidas sobre qué fruto comer o de qué depredador huir valían más que el análisis exhaustivo— pero esos mismos atajos nos dejan en pelotas ante cualquier sistema diseñado para explotar nuestros sesgos.
Y casi todos lo están.
“Soy consciente de que mi elección no es libre, pero es suficientemente bueno para mí, si al menos no me embrutece.”

Estás leyendo ZERO PARTY DATA. La newsletter sobre actualidad y derecho tecnológico de Jorge García Herrero y Darío López Rincón.
En los ratos libres que nos deja esta newsletter, resolvemos movidas complicadas relacionadas con la normativa de protección de datos personales e inteligencia artificial. Si tienes de alguna de esas, haznos así con la manita. O contáctanos por correo en jgh(arroba)jorgegarciaherrero.com

“Aplica la doctrina Scania en la práctica”: segunda edición en Junio
Este mes de junio (los tres primeros lunes) volvemos con nuestra formación presencial, online y socrática sobre la teoría y aplicación en la práctica de la doctrina SRB / Scania.
Todos los detalles aquí, apúntate pinchando en el botón.
🗞️Noticias del Mundodato 🌍
.- Seguimos prestando atención a la dialéctica IA legal contra herramientas especializadas con este long post de Sean A. Harrington: sobre las barreras competitivas que dificultan la generalización de la IA legal.
Las barreras estructurales impiden que la IA transforme la práctica legal, a pesar de que el 79% de abogados afirman usar IA. Sean Harrington analiza cinco obstáculos principales:
(i) el foso competitivo del acceso a bases estructuradas y completas de datos (solo Westlaw, Lexis y vLex/Fastcase poseen bases de datos legales completas en USA, aunque alternativas open-source como CourtListener y el Caselaw Access Project de Harvard erosionan esa ventaja);
(ii el desorden organizacional interno en cada despacho (ESTA ES LA FUNDAMENTAL, BABY BOY) (datos fragmentados en sistemas incompatibles, gobernanza de partnership que da poder de veto a cada socio, falta de liderazgo tecnológico en firmas medianas);
(iii) la paradoja de eficiencia (la facturación por horas desincentiva la automatización, aunque modelos de tarifa fija como ADVOS Legal y Hello Divorce capturan las ganancias de eficiencia en lo que yo llamo el “nicho que nadie quiere”);
(iv) los riesgos de supervisión (el “supervision gap” de Danielle Benecke: cuando los sistemas agénticos manejan flujos completos, la revisión humana total se vuelve económicamente irracional) (esto ya lo comentamos aquí) ; y
(v) la brecha de acceso a justicia (86% de problemas legales civiles de estadounidenses de bajos ingresos no reciben ayuda adecuada).
Especialmente triste el caso de Microsoft Copilot, diseñado como el asistente que ayudaría a los abogados allí donde trabajan: en word: fue calificado como “mínimamente útil para trabajo legal” por consultores de Clear Guidance Partners tras un año de pruebas en múltiples firmas. Microsoft tenía solo 8 millones de usuarios activos de Copilot de 440 millones de suscriptores M365 en agosto de 2025, una tasa de conversión del 1,8%, revelando el fracaso del vendor de software empresarial mejor posicionado para vender herramientas de IA a su base de clientes existente.
.- LinkedIn escanea silenciosamente las extensiones instaladas en tu navegador basados en Chrome y las vincula a tu identidad profesional verificada. Cada vez que un profesional accede a LinkedIn mediante Chrome, Edge, Brave u Opera, un JavaScript oculto escanea hasta 6.278 extensiones instaladas, cifra los resultados y los transmite a los servidores de LinkedIn, donde quedan asociados al nombre real, empresa e historial profesional del usuario. El sistema, que nunca ha sido informado en su política de privacidad, es objeto de dos demandas colectivas federales en Estados Unidos y una denuncia ante la Comisión Europea. El listado incluye 509 herramientas de búsqueda de empleo (1,4 millones de usuarios combinados), extensiones religiosas, herramientas de accesibilidad que revelan discapacidades, lectores políticos y más de 200 competidores directos de productos LinkedIn.
La escala del scan se incrementó desde 38 extensiones en 2017 a más de 6.000 en febrero de 2026, un incremento del 1.252% en dos años. LinkedIn justifica la práctica como herramienta antifraude contra scraping, pero investigadores independientes encontraron en la lista extensiones para programar entregas de Amazon, herramientas de farmacia y descargadores de imágenes, sin conexión plausible con la justificación alegada por LinkedIn.

.- Los mismos profesionales que en 2023 hicieron huelga para protegerse de la IA ahora entrenan a las IAs que compiten con ellos. Es posible que lo hayas leído de trabajadores haciendo tareas de Reinforced learning en Congo o Venezuela, pero la cosa está llegando la mundo desarrollado mucho más rápido de lo que pensábamos.
Interesantísima crónica de Ruth Fowler en Wired: Un escritor de Hollywood entrena IA para pagar el alquiler. Ruth Fowler, guionista y showrunner, relata en primera persona cómo durante ocho meses completó veinte contratos de formación de IA en cinco plataformas distintas (Mercor, Outlier, Turing), ejecutando tareas de anotación, evaluación de chatbots y "red-teaming" de outputs peligrosos.
La promesa de flexibilidad y tarifas altas se choca con la realidad de incorporaciones caóticas, cancelaciones de proyectos sin aviso, acceso revocado instantáneamente y tareas que desaparecen antes de poder completarlas. Si ustedes me permiten otra profecía digan de la más pesimista Casandra: si hay una práctica judicial de futuro es la de la defensa de empleados de plataformas: la cadena de suministro de los datos de entrenamiento engulle trabajadores altamente cualificados sometidos a condiciones precarias que hasta hoy asociábamos a cosas como Glovo y Úber.
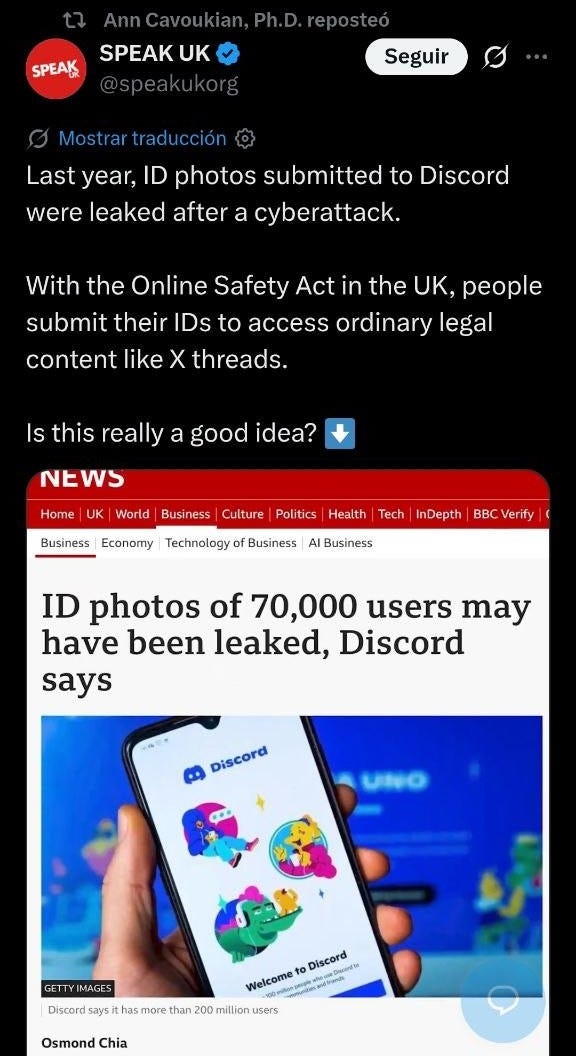
.- Nos quejamos en el lado UE de cómo van Discord y el resto con el tema de la verificación de edad, pero en el lado UK está con plena diversión con banderas. Lo gracioso es que las advertencias del riesgo de suplantación y peor por andar dando el DNI/Pasaporte/cédula identificativa son anteriores a que se fuera del club (por ejemplo, las directrices de ejemplos de brechas del EDPB). Ese dato persona ordinario que acabo siendo sensible sin ser de “categoría especial”. Aquí se suma el peso de que lo comporta la propia Cavoukian en X.
📖 Documentos dateros muy cafeteros ☕️
.- El ICO ha actualizados sus directrices sobre tratamiento de datos de menores, bajo su muy particular Data (Use and Access) Act (DUAA). Aunque no sean ya del club, siguen diciendo cosas a tener en cuenta. Destacamos los siguientes dos pantallazos de consentimiento y decisión totalmente automatizada con efectos “divertidos”.


💀Death by Meme🤣
🤖NoRobots.txt o Lo de la IA
Otra semana más con borrador de directrices de la Comisión Europea. Ahora en forma de borrador sobre sistemas de alto riesgos de IA, abierto a consulta pública hasta el 20 de junio. El borrador de la directrices y de los dos anexos de IA de alto riesgos: una matrioska de tres muñecas.
Entre otras cosas,
La ampliación del margen de adaptación:
The provision further provides that providers and deployers of high-risk AI systems intended to be used by public authorities shall, in any event, take the necessary steps to comply with the requirements and obligations for high-risk
AI systems by 2 August 2030. Article 111(1) AI Act provides a special regime for AI systems that are components of the large-scale IT systems established by the legal acts listed in Annex X AI Act which have been placed on the market or put into service before 2 August 2027. Those systems should be brought into compliance with the high-risk requirements of the AI Act by 31 December 2030
Que un sistema de uso general puede llegar a considerarse de alto riesgo por defecto, si en toda la documentación (instrucciones de uso, contrato, políticas, materiales de venta y documentación técnico) el provider no aclara y aplica limitaciones para dicha variable de uso de alto riesgo
A juego, que acabará siendo declarado como provider, el distributor, importer o deployer que modifique sustancialmente el sistema o cambia su propósito previsto hacia el alto riesgo.
Mucho mejor explicado lo que contiene este borrador de directrices, en el siguiente vídeo de Robert Bateman.
🛠️Herramientas útiles
.- Damien Charlotin mantiene la base de datos más completa de casos de alucinaciones de IA en la práctica judicial mundial, con 1.455 casos identificados hasta la fecha, rastreando decisiones judiciales de tribunales de todo el mundo en las que se estableció que una parte confiaba en contenido alucinado por IA generativa, típicamente citas falsas pero también otros argumentos generados por IA. La base de datos es consultable por país, parte, herramienta de IA y resultado judicial. Los casos abarcan desde Argentina hasta Zimbabue, con Estados Unidos representando 1.004 casos, seguido por Canadá (152), Australia (74) e Israel (52). El 86% de los casos involucraron a litigantes pro se, mientras que 554 casos involucraron abogados.
.- El Irish Council for Civil Liberties ha liberado Verity MCP, una herramienta de código abierto que minimiza las alucinaciones emitidas por los LLMs mediante siete capas de verificación: reglas estrictas de citación, LLM de diferentes familias, inferencia de lenguaje natural (NLI), recomputación aritmética determinista, muestreo de consistencia, análisis de perplejidad y resolución de disputas entre críticos. Es funcional en hardware modesto (una GPU de 2019 como secundaria) y se integra con LM Studio.
Verity produce segundas opiniones simultáneas usando una GPU secundaria mientras el modelo primario responde, permitiendo que ambas respuestas sean evaluadas.
🙄 El chorradón final
.
Si echas de menos algun doc, comentario o chorradón que manifiestamente debería haber estado en el Zero Party Data de la semana, escríbenos o deja un comentario y lo valoraremos para la próxima.
“Había honestidad en la desvergüenza.”
Tengo la sensación de que de aquellos polvos estos lodos.
Vamos, como que entonces no teníamos más medios para ser desvergonzados, y en cuanto los hemos tenido hemos entrado a saco
No sé, es mi percepción 🤔
Interesante el artículo 👏🏼