

#62 “Half the tokens, same price” – Shrinkflation hits AI
... and it's only just begun.
Everyone was saying it. You knew it. Your brother-in-law knew it.
Your €20 AI subscription was being subsidized.
The first one is free.
Buy today and pay tomorrow.
But ah! 2026 is the year of IPOs and, once again, there won’t be enough bread for so much sausage.
They’ve already sold us the chimera; now they have to sell us valuations that are, ahem, solid, based on the bottom line of, ahem, serious financial projections.
So the time has come to raise prices so that revenue projections don’t look quite so terrifyingly disconnected from CAPEX projections.
And that’s where we are: Anthropic and OpenAI have severely guillotined the tokens linked to their subscriptions. Anthropic had already cut the unlimited token buffet for agents. Google is launching paid Gemini plans while also tightening the free tier. Copilot has also moved to pay-per-token consumption, causing quite a mess on GitHub.
I was commenting with Sergio Maldonado that we’ll tell our grandchildren we lived through the golden age when “they were giving it away.” Well, kid, that’s over now.
And prices will keep rising vertically, make no mistake: there is no hiding that this technology is very expensive, and this has only been the first step. This increase does not bring the matter anywhere remotely close to profitability.
In 2026 we will still see smiling faces in the AI technocracy. But once they’ve managed to offload a good fraction of gold-priced shares onto us, it will be time for the fangs.
Wave goodbye to spending the afternoon generating 50 silly images to share with the family. Say farewell to wrappers and token resellers.
Get ready to upgrade your plan and still burn through it in a couple of prompts.
Say “Hello” to open models.
Hold on tight: Winter’s coming.

You are reading ZERO PARTY DATA. The newsletter about tech and legal affairs by Jorge García Herrero and Darío López Rincón.
In the free time that this newsletter leaves us, we solve complicated issues related to personal data protection regulations and artificial intelligence. If you have any of those, give us a hand. Or contact us by email at jgh(at)jorgegarciaherrero.com
🗞️News of the Data-world 🌍
.- First news that an association of age verification solution providers has been established (Age Verification Providers Association), but they come out swinging in this LinkedIn post attacking the AEPD’s decision against YOTI. And calling for the EDPB to issue specific guidance on the matter. Something similar to last year’s declaration, Statement 1/2025 on Age Assurance? Or perhaps the more recent joint opinion with the EDPS on the possible change to the Article 9 exception for verification necessity through the Digital Omnibus?
Far from trying to play the strongest card of arguing that this is biometric processing not prohibited by Article 9 because it does not have the purpose of unique identification, they almost seem to acknowledge that there is no other way to do it. Therefore, we might begin to suspect that all alternatives follow essentially the same template as Yoti. Bleeding all the way to the million-euro mark from the same wound: Article 9 processing that is difficult to legitimize.
They criticize the AEPD somewhat for pointing out the obvious problem of consent, but there isn’t much else available. Legal obligation doesn’t work (the DSA doesn’t allow it in the required way), and legitimate interest must be built around the Gordian knot of proportionality and necessity. Especially now that a supposedly less intrusive alternative is arriving in the form of the EU app. And there they push back somewhat on the point that relying on a PIN carries the clear risk of “shoulder-surfing” attacks.
It also doesn’t help when the argument is framed in very COVID-era terms of simply having something that works:
“The AEPD’s decision, by treating the biometric facial template within a consumer identity app as special category data that cannot be made a condition of service, points toward a future in which the most secure authentication option is legally the most difficult to deploy. The least secure option is the path of least regulatory resistance.”
Nor does it help that the Digital Omnibus, regarding the GDPR section, appears—unless things change—to require exclusive control by the data subject in order to apply the exception. Exactly the opposite of how these systems operate.
A good opportunity to remember the EDPB’s dual possibility regarding biometric processing under Article 9 and non-Article 9 biometrics. In those very guidelines that overturned the previous interpretation assumed by the AEPD.
.- In relation to the same issue, it is worth remembering that this technology fails spectacularly: case in point, The United Kingdom mistakes children for adults. New Home Office figures reveal that, in the second half of 2025, 17% of migrants classified as adults turned out to be minors.
The practical consequence? Minors wrongly classified as adults ended up sharing rooms with adults without any safeguards, according to the Helen Bamber Foundation, which documented cases involving children as young as 14. Now imagine your own child in that situation.
The Helen Bamber Foundation, the British Association of Social Workers, and Human Rights Watch warn that AI reproduces biases and fails to account for the effects of trauma, malnutrition, and exhaustion on the physical appearance of minors.

.- Regarding the less discussed DMA, THE General Court of the EU annuls the Commission’s decision designating Meta as a gatekeeper in its marketplace. However, it considers the designation appropriate regarding the separate “Messenger” service.
.- This European Parliament document on the “debate” around the minimum age for social media is quite interesting. In a relatively short document, we get a linked compilation of the main legislative attempts by multiple countries to achieve this impossible objective, references to the rather underwhelming Australian experience, a collection of minimum consent ages across EU countries (Spain keeps talking about 16, but not yet), the French case that advanced legislation until the Commission stepped in, and what we already know about the GDPR, DSA, and EU Identity.

.- Another blow delivered by Dr. Ferguson, but it is satisfying when knowledgeable people simply keep stating facts plainly.
And with solid reasoning, via Substack. The important thing is not merely to say it, but to argue it as convincingly as possible.

Do not miss the following article: save it for the weekend or do whatever you need to do, but don’t miss it: The messy middle reflects with disarming humility and clarity on the challenge we will face as a society until the supposed universal benefits of AI and automation arrive. If they arrive (for everyone). Well-grounded and filled with excellent charts, this article should never let you sleep well again. You’re welcome.
As an example, here’s one.

.- Adtech: Excellent article by Abhi Yadav: First-party data theatre regarding Publicis’ acquisition of LiveRamp, one of the most despicable companies I’ve ever had to go toe-to-toe with. First-party data (1PD) had its heyday as a response to the tyranny of Meta, Google, Apple, and the other “walled gardens” (territories where trapped consumers could be offered products and services under the conditions imposed by the local feudal lords).
The author explains transparently how service providers for exploiting 1PD actually take ownership of the inferences extracted from the data, turning the owner (the responsible company) into a servant. Added to that is the fact that inferred data becomes more valuable the more first-party data flows into the pool, but—for the same reason—the larger you are, the more profitable it becomes. The counterintuitive moral is that your competitors can eat your lunch using your own first-party data if they hire the same platform you do.
If you are not clear that these types of platforms routinely identify data subjects even when they have different IDs or hashes for each client, it is because you do not remember the Criteo case.

.- AI rewrites consumer contracts. This article struck me because of how accurate it is: Dave Hoffman weighs different scenarios in which companies respond with AI to the flood of complaints that consumers can now generate very easily. The reaction could be either longer, more tedious, and more detailed contracts, or more ambiguous clauses.
What is interesting is that he places the real leverage in historical data regarding each consumer’s willingness and tendency to litigate (in my case, I rarely file complaints, but when I do decide to go all in, I really go for it—right, Meta and El Corte Inglés?).
📖Hard data docs for coffeine lovers☕️
.- The CNIL sanction against IQVIA is packed with interesting points: we produced an extensive note and here you can read an excerpt.
.- Saint Luis Montezuma brings us the latest report from the Norwegian authority, which asks whether it is legally possible to offer AI-based chatbots anonymously. The document reviews the liability framework applicable when an operator intends not to identify itself, the conditions under which anonymity could be compatible with the GDPR, and the steps necessary for such a model to be lawful. The approach is interesting because it addresses the perspective of a provider seeking to offer its service while minimizing regulatory exposure.
More from Luis: the Lower Saxony Data Protection Authority published FAQs on the use of AI, while the Belgian Authority completed an investigation into a smartphone conversational application that uses AI and language models.
.- SuperMario Guglielmetti raises a very interesting point regarding the famous warning issued by the Garante to Myndoor over the plugin that read workers’ conversations in Slack and Teams to detect psychological stress: if the analysis is based on text and not biometrics, it may not constitute emotion recognition.
For my part, I would add that the provider cleverly relied on each worker’s consent to process their data, but where I come from conversations involve third parties, and those people probably neither knew about nor could object to such a delightful form of processing.
💀Death by Meme🤣


🤖NoRobots.txt or The AI Stuff
.- Two gems from 404:
The first is a story that took me a while to believe: Meta’s chatbot gave away Instagram accounts. Pro-Iranian hackers compromised high-profile accounts—including the archived White House account from the Obama era, Sephora, and a senior U.S. Space Force officer—by exploiting a vulnerability that seems designed by someone with a severe cognitive deficit. The attackers simply asked Meta’s support chatbot to link the target account to a new email address. Zuckerberg’s team had handed the palace keys to the bot, giving it permission to make account changes, generate a verification code, and send it to the attacker.
Meta integrated AI support into all Facebook and Instagram accounts in March 2026 with password recovery capabilities. Victims report that there is no way to escalate the issue to a human operator.
As I said, difficult to believe even for a skeptical bald man.
.- The second: Microsoft wants you to become addicted to Scout. Internal Microsoft documents leaked to 404 Media reveal that the plan for Scout—the OpenClaw-based personal assistant integrated into Microsoft 365 and announced this very week—is structured in three phases, with the first phase explicitly being “make people addicted.”
Well then.
.- This story has already gone viral, but it remains one of the most interesting stories around. We already had one involving AI-generated documentation that made it into a U.S. courtroom, but we were still missing the lawyer trying to fool the AI performing the first case screening in Brazil. A textbook prompt injection, but in an evolved form of the old trick of hiding something that only the AI processing the CV sees first.
We will see many similar stories across the thousand filters that public administrations will introduce into citizen procedures. And judges resisting the temptation to conduct speculative investigations based on a defendant’s face.
.- Really interesting article about the AI actress nobody asked for. The New York Times Magazine presents a detailed profile of Tilly Norwood, the first entirely AI-generated “actress,” created by Eline Van der Velden through the Xicoia studio.

📃Paper of the week
.- Bring Your Own Device — Now Hand It Over! Rescuing Workers’ Privacy During Data Searches by Virginia Mantouvalou and Michael Veale. The BYOD (Bring Your Own Device) practice and personal-professional cloud storage create gray areas where employers may legitimately require access to a worker’s devices and data—based on data protection laws, freedom of information obligations, or procedural law—without any effective separation between the private and professional spheres.
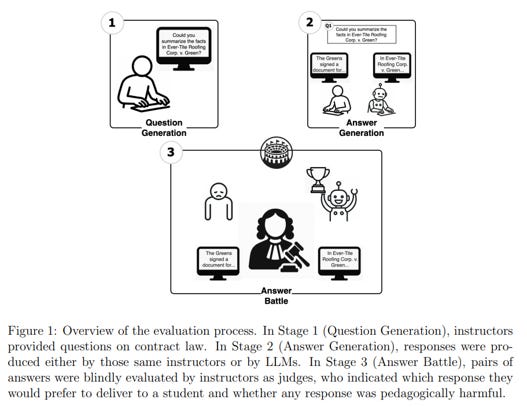
.- A paper presenting the opposite side of the story from an LLM inventing case law citations or legal reasoning. In an experiment comparing whether an LLM or a professor would better answer questions from first-year law students (in the U.S. course known as “Contracts”), the LLMs won by a landslide with roughly 75%. They were also friendlier, though that is nothing new. AI always flatters you. Seen via Ethan Mollick on LinkedIn.
Jorge’s postscript: I would like to see the same study with LLMs, university professors, and practicing lawyers competing against each other.
🛠️Useful tools
- Following the publication of the AEPD’s 1,500 reports, we now have two inventions:
Rumpelstiltskin: our own little goblin.
The Claude artifact version by Jorge Morell that we were all waiting for when the AEPD released the reports.
🙄 Da-Tadum-bass
If you miss any doc, comment, or dumb thing that clearly should have been in this week’s Zero Party Data, write to us or leave a comment and we’ll consider it for the next one.