

Análisis de alto nivel sobre Atlas, el nuevo navegador de OpenAI
"Tengan mucho cuidado ahí fuera"
Lo que viene a continuación es un análisis de alto nivel sobre la arquitectura de “Atlas” de OpenAI y los riesgos más llamativos a la luz del RGPD y el RIA.
Aborda el uso corporativo de Atlas y no entra en la obligación de hacer DPIA o su contenido (queremos mantener un cierto nivel de seriedad) ni cuestiones de transferencias internacionales de datos o medidas contractuales de selección de proveedores o aseguramiento de accountability en ellos (estamos hablando de OpenAI).

Estás leyendo ZERO PARTY DATA. La newsletter sobre actualidad tecnológica desde el punto de vista del derecho de protección de datos e IA de Jorge García Herrero y Darío López Rincón.
En los ratos libres que nos deja esta newsletter, nos gusta resolver movidas complicadas en protección de datos personales e inteligencia artificial. Si tienes de alguna de esas, haznos así con la manita. O contáctanos por correo en jgh(arroba)jorgegarciaherrero.com
Descripción de la Herramienta
Atlas es un navegador con funcionalidades de ChatGPT integradas, disponible de momento sólo para iOS y sólo para modalidades de pago (Plus, Pro, Business, Enterprise/Edu).
El flujo incluye un LLM central (ChatGPT), memoria persistente (“browser memories”), capa agentic (actions/tools), interacción con APIs y fuentes externas de datos.
No se declara el uso de subencargados/cloud externos (BigQuery, GCP, AWS), salvo integración puntual vía agentes; se recomienda su mapeo en DPA.
La documentación disponible no indica política automática de TTL para memorias, logs o contexto persistente: el borrado/archivado es manual.
Resumen ejecutivo o quick-takeaways
Sí: esto va al principio porque sabemos que casi nadie se leerá 2.500 palabras de texto.
Atlas está orientado a productividad personal, con funciones de agente y memoria contextual persistente.
Se recogen y tratan múltiples categorías de datos personales: historial, chats, “browser memories”, contraseñas y marcadores importados.
La base jurídica que parece inferirse de la documentación disponible es (“ejecución de contrato” -términos y condiciones-). Esta base es harto discutible desde un punto de vista riguroso. Dicho esto, se solicita el consentimiento explícito para habilitar finalidades de entrenamiento.
El usuario controla la visibilidad, persistencia y entrenamiento de datos. YES BUT: (i) su consentimiento se capta bajo numerosos dark patterns, y (ii) existen riesgos de todos los colores en contextos de memoria persistente y uso de agentes.
La arquitectura de la Herramienta implica tratamientos por OpenAI (Provider) y control por parte del usuario o su organización (Deployer).
Existen controles documentados para minimización, TTL y acceso, pero política de retención/logging no detalla plazos; el control recae en el usuario, algo que siempre socava cualquier valoración de la accountability del provider.
El flujo agentic y la integración de fuentes externas (correo, docs) amplifican riesgos de propagación, exfiltración o inferencia no prevista de datos personales, principalmente, pero no sólo, por el riesgo de prompt injections.
No se identifica como sistema de alto riesgo bajo Anexo III del AI Act, pero su uso en el entorno de cualquier organización requiere DPIA por tecnología innovadora, acceso y combinación de datos, gran escala y potencial inferencia de categorías especiales, a vuelapluma.

Si quieres conocer a más zumbados de la protección de datos y la IA, y de paso colaborar en una causa solidaria, te esperamos el 28 de Noviembre en la Comida Sirera.
¿Te acuerdas del episodio de Friends de Ross en el congreso de paleontólogos? Esto es lo mismo, pero más divertido. Apúntate en este enlace: https://bit.ly/Comida28N
Mini-análisis RGPD — Base jurídica, transparencia, minimización
Base jurídica:
· Funcionalidad principal: De la documentación disponible para inferirse: ejecución de contrato (art. 6.1.b), pero en rigor esta base sólo cubriría los tratamientos estrictamente necesarios para cumplir la funcionalidad prometida por la Herramienta (chat, navegación, respuestas).
· Entrenamiento de modelos de IA de OpenAI: Requiere consentimiento explícito (art. 6.1.a RGPD); el usuario debe habilitar la opción “include web browsing” para que su contenido sea usado para esta finalidad.
Transparencia:
El usuario controla la visibilidad y persistencia de memorias, pero debe clarificarse cómo la configuración previa de ChatGPT afecta a Atlas (recomendación: deberían implementarse instrucciones y onboarding específicos, Atlas puede resultar realmente pesado para obtener consentimientos del usuario).
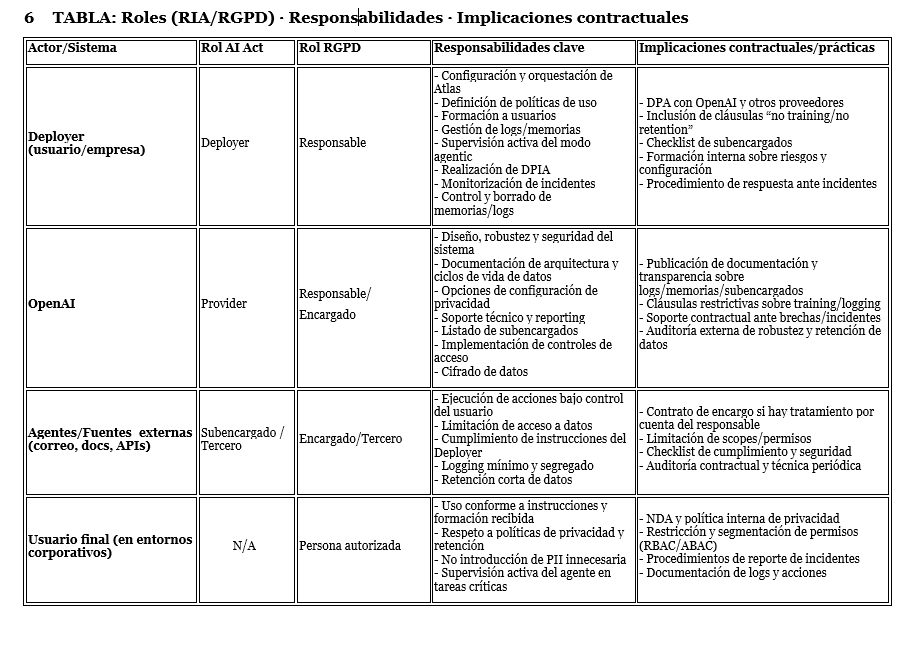
Mini-análisis RIA
Provider: OpenAI (ChatGPT Atlas) es el provider; y debe determinar la robustez, seguridad del sistema y las condiciones de uso.
Deployer: La organización que ofrece Atlas a sus empleados (o la que sujeta a terceros a, por ejemplo, los efectos de lo que Atlas en modo agentic haga) actúa como deployer, asumiendo control de uso, configuración, orquestación, logging y supervisión humana.
Otros roles: Agentes/fuentes externas pueden funcionar como subencargados o terceros independientes (correo, docs, web).
Alto riesgo (Anexo III): No aplica la clasificación como alto riesgo per se (orientación productividad/personal), pero la funcionalidad agentic (acciones autónomas) implica riesgos relevantes en seguridad y privacidad, y requiere monitorización constante y advertencia activa al usuario.
Flujo de datos y principales cuestiones
Atlas integra varios flujos diferenciados que, en conjunto, conforman una arquitectura compleja susceptible de introducir riesgos acumulativos de privacidad.
Interacción directa usuario–ChatGPT
El usuario interactúa con el navegador Atlas abriendo una nueva pestaña, introduciendo una URL o una consulta en lenguaje natural. Esta petición se transmite al motor LLM (ChatGPT), que realiza el tratamiento, búsqueda y razonamiento contextual para devolver una respuesta enriquecida, pudiendo incluir enlaces, imágenes, vídeos o extractos relevantes. El ciclo es inmediato y está enfocado a proporcionar soporte o asistencia durante la navegación.
Ojo: El input del usuario puede contener datos personales, que además pueden ser de categoría especial.
Mucho ojo: Además, debido el diseño de Atlas, la respuesta puede ser personalizada a partir de contextos persistentes previos (browser memories), ampliando la ventana de exposición potencial de la PII.
Este es un gran problema escondido a simple vista: el usuario que usa Atlas no necesariamente navegará por webs de internet, sino por una amalgama de contenido sintético generado por ChatGPT, a través de una interfaz que parece un navegador.
Memoria persistente de datos de navegación
Atlas incorpora una funcionalidad de memoria contextual persistente denominada “browser memories”, mediante la cual el sistema extrae, almacena y re-utiliza detalles clave de la navegación web.
Este proceso ocurre cuando la “visibilidad” está activada y puede alcanzar desde fragmentos de texto hasta metadatos de interacción (tiempos, patrones de uso, páginas visitadas).
Implicaciones: A diferencia del historial tradicional, estas memorias se emplean de forma activa para enriquecer futuras respuestas de ChatGPT, ofreciendo sugerencias personalizadas y recordatorios inteligentes (por ejemplo, sobre artículos consultados semanas atrás).
Control y riesgos: No existe un TTL automático, la gestión es manual y depende del usuario: las memorias pueden archivarse, visualizarse y borrarse, pero su persistencia por defecto incrementa el riesgo de inferencia sobre hábitos, intereses y categorías especiales de datos (p. ej., salud, finanzas, ideología), como advierte el propio documento de referencia. El control de estas memorias es fundamental, ya que su uso puede derivar en perfiles detallados de comportamiento y preferencias.
Funcionalidad agentic y acceso a herramientas externas
En modo agente ChatGPT puede ejecutar acciones autónomas que van más allá de la simple generación textual.
Incluye la posibilidad de interactuar con fuentes externas (correo electrónico, repositorios de documentos, hojas de cálculo), realizar investigaciones automatizadas, cumplimentar formularios e incluso efectuar compras o reservas.
El usuario mantiene la capacidad de pausar, interrumpir o supervisar al agente en cualquier momento.
Cuestión: Esta capa incrementa los riesgos de exfiltración accidental o masiva de datos personales, al
(i) permitir prompt injections y
(ii) conectar ChatGPT con APIs de terceros que pueden operar bajo estándares de privacidad y seguridad no alineados con los de OpenAI o el usuario final.
Es esencial destacar el riesgo de exfiltración inadvertida de datos personales e información confidencial, transmisión de parámetros excesivos y persistencia no gestionada de contexto en sesiones complejas.
Importación inicial
Al instalar Atlas, el usuario puede importar contraseñas guardadas, marcadores e historial de otros navegadores. A lo largo del uso, el historial de chats y la memoria se almacenan en la cuenta de usuario, salvo cuando se activa el modo incógnito o se efectúa un borrado manual. Las páginas visitadas por el agente no se incluyen en el historial estándar del navegador, aunque el documento no detalla la retención de logs técnicos (debug) ni su ubicación concreta.
Cuestión: La importación masiva de datos personales (especialmente contraseñas y marcadores) puede suponer un riesgo si el sistema no aplica segmentación de acceso, cifrado fuerte y supervisión activa. La ausencia de un mecanismo automatizado de expiración o borrado de logs refuerza la necesidad de controles contractuales y técnicos.
Persistencia y logging
El sistema guarda persistentemente tanto el historial de chat como las memorias, sin TTL automático. La persistencia puede comprender periodos indefinidos salvo intervención manual. No se especifican políticas de logging para depuración, ni la localización física del almacenamiento (cloud/local), ni los mecanismos de cifrado o control de acceso aplicados.
Conclusión: Tenga mucho cuidado con todo esto:
Importación de contraseñas/marcadores/historial desde otros navegadores.
Creación y uso de “browser memories” sin directivas de supresión automática.
Inclusión de contenido web adjunto en los chats (abonado a mix de contextos privados/profesionales).
Interacción con fuentes externas (correo, docs, hojas de cálculo) y ejecución de acciones automatizadas. (Bomba de relojería).
Logging del historial de chats y memorias, persistente salvo uso de modo incógnito. (Pero… ¿Alguien utiliza aún el modo incógnito pensando que sirve para algo?).
Exclusión de logging para navegación agentic, pero posible persistencia en otros componentes.
Más sobre esto, con ejemplos muy específicos de ataques de tercero en el Brave blog, en el Washington Post, y en este cluster post de Natzir T.
🗞️Noticias del Mundodato🌍
.- El EDPS ha actualizado sus orientación de IA Generativa/GAI. Te podríamos meter aquí más rollo que lo previo que has leído con las novedades, pero Joost Gerritsen lo cuenta muy bien por Linkedin.
.- Otro lío más para Clearview. Ahora en ámbito penal desde Noyb. Recuerden el póker de DPA sancionando, el cachondeo de estos señores por su base de datos biométricas de quién sabe y las dudas desde el EDPB para que las autoridades policiales lo usen para lo que ya sabemos (indirectamente, a través de cuestión remitida por la sospechosa habitual, Sophie in’t Veld + algún otro europarlamentario más)
.- El Garante italiano avisa de que el 3 de noviembre empieza el entrenamiento de IA con datos de Linkedin, a efectos de dos cosas: que nos podamos todos oponer si queremos, y para decirnos que anda con otras DPAs viendo si lo de Linkedin cumple en oposición/baja e IL sólido. Mira que cada vez funciona peor para no ver morralla, pero era lo que quedaba después de Elmo(X).
.- La Datatilsynet se ha pronunciado sobre la Doctrina Scania. Es la primera autoridad que lo hace. Y para mi gusto, ha metido la pata hasta la rodilla, pero sólo es mi opinión.
💀Death by Meme🤣
Y como el día siguiente del lanzamiento de Zero Party es Halloween, tocaba hacer mención al tema. Se podría hacer una versión específica de algo datero, pero nunca se podrá superar lo que se vió por Linkedin el año pasado. Es un breve selección de los cuatro más conocidos para que nadie se ofenda, pero en el post original de Marc Beierschoder hay más:

!Hasta la próxima semana!
Si te ha gustado Zero Party Data, compártelo, no seas asín.