

I’m writing this on Tuesday after noticing that people do not perceive the importance of the C-188/24 (WebGroup Czech Republic) and C-190/24 (Coyote System) judgments of the CJEU. Press release and link to the ruling.
It is time to get a bit dramatic:
1.- In October 2021, Frances Haugen sat before the United States Senate Commerce Committee and revealed thousands of internal Meta documents.
The most devastating ones described what the company knew and concealed about the impact of its recommendation algorithm on teenagers. Instagram’s internal research concluded that the system redirected young girls toward content related to eating disorders and misogyny, even if they were not actively looking for it.
2.- The documents disclosed by Meta in the context of litigation in New Mexico reveal —we told it in March— that the company knew that its algorithm suggested four times more accounts of minors to potentially dangerous adults (prone to grooming and sextortion).
Almost one in four of these adults (attention: one in four (!!!) actually tried it (the data comes from the documents).
Did Meta correct this as a result of these data?
No.
Meta reviewed the facts and did not change the algorithm: it is not a bug but a feature when your ultimate goal is engagement optimization, and engagement increased with these practices.
The worst part is that there is no need to resort to leaked documents, if one has eyes in one’s face.
3.- Last week, a 15-year-old girl described in The Guardian the content she finds on Instagram and TikTok without looking for it: comments about other girls’ bodies, videos with degrading jokes, material that trivializes domestic violence or rape. She explains how she actively tries to avoid it, but finds it incessantly as soon as she opens her apps.
It is the same phenomenon documented by Frances Haugen with corporate slides, but it personally impacts me much more in the words of this young woman.
The recommendation systems of these platforms do not rank what the user wants to see, but rather the content that knowingly increases screen time “spent.” Engagement is the objective, but it is achieved on the backs of material that generates strong emotions and reactions —outrage, social comparison, fear…—.
If I had Instagram, The Guardian article (or rather some bro’s post laughing at it) would appear among the very first things in my feed.
4.- The CJEU has just declared that if a platform uses an algorithm to determine, in its own interest or in that of its service, the conditions, form or order of priority with which its users’ information is disseminated or displayed, it is exercising active control over the content.
And that control deprives it, according to the CJEU, of the liability exemption provided for in the ecommerce Directive for platforms that host third-party content.
The recommendation algorithm destroys the intermediary’s neutrality with respect to the content hosted by its users. That includes:
The racist memes your children see on Instagram, YouTube and TikTok.
The irrelevant content Google returns to you.
The dodgy, pricey, but “recommended” products on Amazon.
The obvious scam attempts Twitter shows you. And Elon’s nonsense.
The most expensive flat (but the one that appears first) on Idealista or Airbnb.
The AI slop songs Spotify foists on you because why not.

In the words of the CJEU:
111 As the Advocate General stated, in essence, in point 239 of his Opinion, it is, inter alia, by means of the algorithm used that such an operator exercises control over the information stored. So long as it has predetermined, by means of that algorithm, the conditions under which such information may or may not be broadcast, it is irrelevant that that operator does not itself carry out additional interventions which have the effect of promoting, modifying or deleting information stored with a view to it being broadcast.
112 In that regard, it must be made clear that if, beyond the mere categorisation and indexation of information for the purpose of improving its accessibility, the algorithm used determines, in the interest of the operator or its service, under what conditions, how and in which order of priority that information is or is not be broadcast, that operator exercises control over that information, with the result that the service it offers cannot be classified as an ‘information society service … that consists of the storage of information provided by a recipient of the service’, within the meaning of Article 14(1) of Directive 2000/31 (see, to that effect, judgments of 23 March 2010, Google France and Google, C‑236/08 to C‑238/08, EU:C:2010:159, paragraphs 115 and 117; of 12 July 2011, L’Oréal and Others, C‑324/09, EU:C:2011:474, paragraph 116; and of 22 June 2021, YouTube and Cyando, C‑682/18 and C‑683/18, EU:C:2021:503, paragraph 114).
5.- Last but not least: the fact that age verification —one of the recurring topics in this newsletter for all the worst possible reasons— has been the excuse for the CJEU to issue this monumental ruling is a plot twist worthy of M. Night Shyamalan.
Tuesday was a historic day. It remains to be seen how things evolve.
Because no one overlooks the fact that Schrems II was of very little use.

You are reading ZERO PARTY DATA. The newsletter on technology and legal news by Jorge García Herrero and Darío López Rincón.
In our free time from this newsletter, we resolve complicated issues related to personal data protection regulations and artificial intelligence. If you have any such issues, give us a hand. Or contact us by email at jgh(at)jorgegarciaherrero.com.
🗞️News from the Data World 🌍
.- The Dutch Autoriteit Persoonsgegevens fined transport app Yango €100 million for transferring personal data of users and drivers to Russia without adequate safeguards (yeah, as if there were adequate safeguards if you’re transferring data to Russia).
The Standard Contractual Clauses (SCCs) were intended to compensate for the deficiencies through pseudonymization and encryption measures, but the Authority found that until November 2023 the encryption keys were stored on the same Russian servers as the encrypted data. In addition, Yandex.Taxi LLC —which controlled the software and determined what data was collected— was classified as a joint controller, invalidating even the SCC model that had been used.
.- South Korea imposes a fine of $408 million on Coupang for the largest data breach in the country’s history. The Personal Information Protection Commission (PIPC) investigated a breach that exposed the data of millions of customers of the e-commerce giant, the Korean equivalent of Amazon. The penalty sets a record for enforcement under Korea’s privacy law, PIPA (and in Asia generally). The PIPC determined that Coupang failed to comply with its technical and organizational security obligations, as well as incident notification and management duties.
.- Starmer continues his personal crusade to tackle digital harms affecting British children. Now by repeating what Australia already did with mixed results: banning social media until age 16. What could possibly go wrong (again)?
And announcing the “ban” on social media through social media itself, with a message adapted to the format of those same platforms (and accompanied by a community note showing more common sense than the average public official).
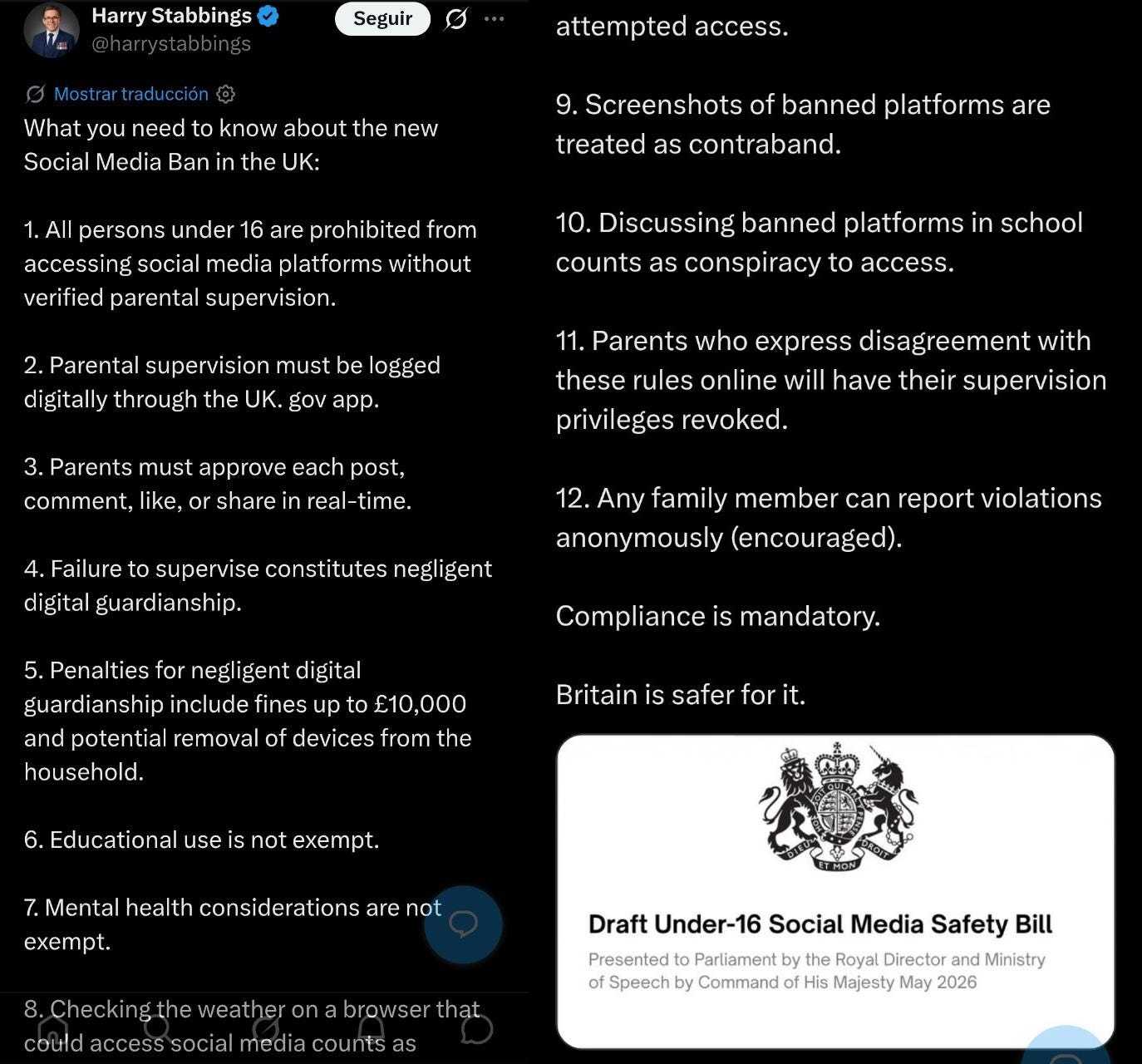
And accompanied by an instant meme of a teenager reacting to the measure, exactly as happened in Australia. “I’d Stare at a Wall!” Stoic resignation or legendary sarcasm?
.- TikTok’s partial victory before the Irish High Court does not mean its data transfers to China comply with the GDPR: the court confirmed the violation of Chapter V, but annulled the DPC’s corrective orders due to insufficient technical reasoning.
The DPC failed to justify why the measures implemented under “Project Clover” were insufficient to prevent re-identification, despite having both the Mittal report and an independent review by NCC Group, both favorable to TikTok.
The case now returns to the DPC for that analysis to be carried out. The non-obvious point: the court did not question the technical adequacy of Project Clover, but rather the quality of the regulatory reasoning; the DPC could reach exactly the same conclusion again if it supports it with rigorous methodology.

.- A Munich court has declared Google liable for incorrect answers provided by its AI Overviews tool.
It has not been a good week for Big Tech. The ruling establishes that, since Google deploys and controls the AI system, it is responsible for the incorrect information it generates, regardless of the fact that the content originates from a probabilistic model. The judgment does not address GDPR issues because the case does not concern a natural person, but it does recognize a violation of the general right to corporate personality. The broader consequence: the court equates deploying an LLM with engaging in editorial activity, something that could transform liability for generative AI providers in Europe long before the AI Act becomes fully applicable.
📖 Hard data docs for caffeine lovers☕️
.- The excellent infographics by Müge Fazlioglu for the IAPP on the interrelationships between the GDPR and:
EU AI Act
Network and Information Security Directive (NIS2)
Digital Services Act (DSA)
Digital Markets Act (DMA)
Data Act
Data Governance Act (DGA)
.- And Robert Bateman’s own infographic on the DPC’s original TikTok decision. It was still longer than the court judgment that sent the ball back.

💀Death by Meme🤣


🤖NoRobots.txt or the AI stuff
.- Claude Fable 5 came and, just as it came, it went away, by the grace of the Dorito. Meanwhile, in the EU we regulate competition out of existence. The joke writes itself.

.- Simon Willison reflects on the product-market fit of generative AI tools. He argues that most products built on top of LLMs still have not found a real fit with the needs of non-technical users. Willison distinguishes between adoption driven by curiosity or novelty and adoption driven by sustained usefulness, pointing out that most of the use cases generating excitement within the industry are led by developers evaluating the capabilities of the models themselves, rather than end users solving everyday problems.
The piece questions the metric of “active users” as an indicator of real value and proposes that true product-market fit in AI will be achieved when models become reliable and predictable enough to operate in critical workflows without constant human supervision.
The non-obvious insight: Willison suggests that reliability —not capability— is the real bottleneck, and that improving performance benchmarks without reducing hallucination rates does not bring models any closer to product-market fit.
.- European Parliament has also approved the AI Act amendments. The most important points:
AI systems that generate CSAM content or nude images, intimate body parts, or horizontal sporting activities involving an identifiable person are prohibited (unless consent has been obtained for that purpose).
Providers that take the risk of using this type of generally prohibited system may attempt to demonstrate that they have real and effective technical measures in place to prevent the generation of such content. The prohibition also applies to deployers, of course.
The new implementation deadlines:
From 2 December 2027 for standalone high-risk AI systems.
From 2 August 2028 for AI systems integrated as safety components and regulated under sector-specific safety and market surveillance legislation.
From 2 December 2026 for the obligation to include watermarking in AI-generated content. The same deadline applies to systems generating CSAM content and “nudifier” content.
Precisely regarding labeling, the Commission’s proposed icons emerged from this discussion. What is mandatory is the labeling and readable marking required by Article 50, but at least here they went further than they ever did with standardized GDPR icons.
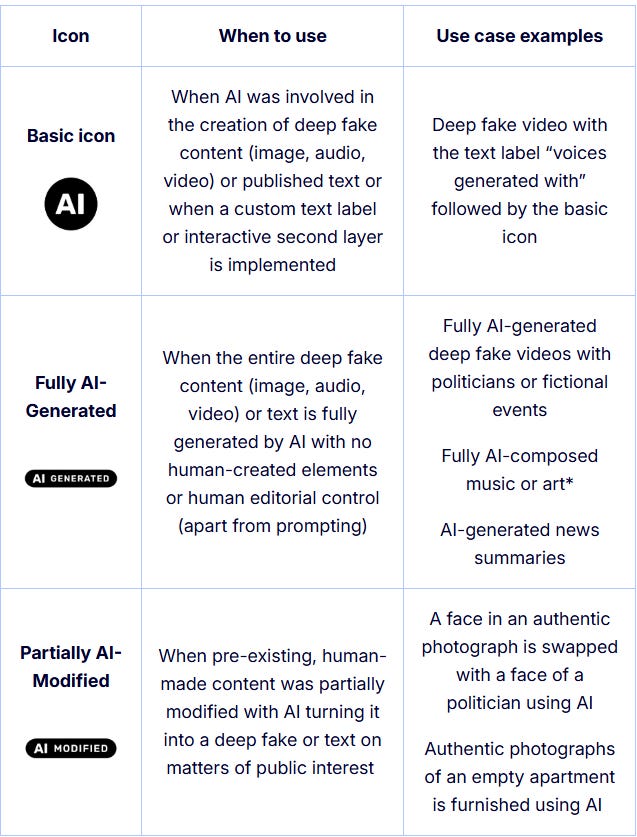
.- The EDPS, in a short Supervisor blog post format, reminds us that shadow AI can become a curious security breach risk.
Organizations need to be alert to ensure nobody uses unauthorized AI applications or services, and it is not a bad idea to implement unauthorized domain blocking, restrictions on corporate devices, and secure alternatives for whatever employees were trying to do on their own initiative.
.- Unexpectedly, we came across an Amnesty International report on the risks of generative AI. Even the title speaks directly to data geeks: Unlawful by Design. It provides a good overview of multiple biases, including certain actions by DPAs in high-profile cases:
The dominance of English creates a bias whereby English-language information is considered more reliable than information in other languages.
Opt-out mechanisms often work poorly.
CSAM content is generated at alarming rates.
Harm and hate scale with model size.
And then there is the following case, which is quite something:

🛠️Useful tools
.- Supertonic is a tool from Supertone for AI-powered voice manipulation and transformation, released as an open-source project on GitHub.
The tool allows modification of vocal characteristics —pitch, timbre, speaking style— through high-quality voice synthesis and conversion models, with applications in audio production, accessibility and content creation.
.- Markus Sullivan publishes a GitHub repository containing all CJEU data protection cases, EDPB guidelines, and the full GDPR text in PDF format, ready for download without scraping scripts or internal permissions. The repository is intended for those who need the data to train models, perform semantic analysis, or simply maintain an up-to-date legal corpus available offline.
And the LinkedIn post, as always, is very funny.
🙄 Da-Tadum-bass!!

If you miss any doc, comment, or dumb thing that clearly should have been in this week’s Zero Party Data, write to us or leave a comment and we’ll consider it for the next one.