

Every prompt you make, AI´ll be watching you
Oooops, they did it again !!
When you use an AI chatbot, it is normal to think that what you write stays between you and your favorite AI provider.
“What happens in Vegas stays in Vegas” and all that jazz.
And in fact, AI providers encourage us to use their models to integrate them into our daily decisions, so that we trust them in increasingly intimate contexts. Supposedly under that premise.
Well, no.
Narseo Vallina and his colleagues at IMDEA NETWORKS have done it again.
As they develop on this website, in a study conducted last April, they have discovered things that might surprise you and disturb you if you chat with AI models via the web (not through the API).
Models like Perplexity, ChatGPT, Claude, or Grok.
Little-known. And that nobody uses.
I invite you to visit the original website. Here, the only thing I am going to do is what I did last time (the Meta localhost scandal): translate what they have discovered into terms that a layperson in technology can understand.
· First, I tell you what they have discovered.
· Second: I explain how it works, how these companies do these things
· Finally, I give you the legal perspective, which has been my part in all this: the responsibilities that these companies may and should face.

You are reading ZERO PARTY DATA. The newsletter on technology and legal affairs by Jorge García Herrero and Darío López Rincón.
In the free time that this newsletter leaves us, we solve complicated issues related to personal data protection regulations and artificial intelligence. If you have any of those, give us a little hand. Or contact us by email at jgh(at)jorgegarciaherrero.com
1.-What have they discovered?
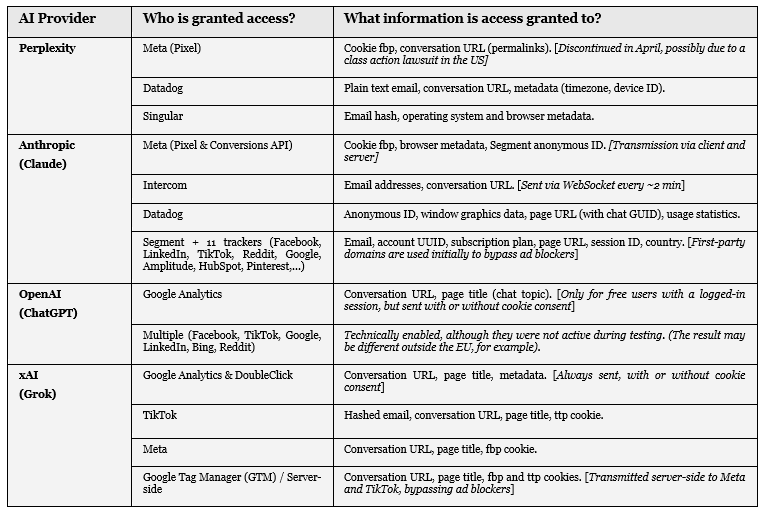
The websites of these four services have open doors on their websites that allow third parties to access your information:
.- Grok and Perplexity: Through Meta’s pixel
.- OpenAI: Through Google Analytics.
.- Claude: Through the Meta pixel, and Facebook, LinkedIn, TikTok, Amplitude, HubSpot, Pinterest conversion APIs, among others.
But “don’t leave yet: there’s more”.
Fasten your seatbelts: this is somewhat similar -at least for some users- to having a video camera pointing directly at their open diary.

“Well, the important thing is that they don’t have access to my ‘private’ conversations with Claude and ChatGPT, and that happens, right? RIGHT? HUH?”
The “title of each chat” is also shared.
This is not very good news: AIs have the bad habit of automatically generating a title for the conversation that summarizes its content, so if the conversation titles are:
“Depression tips”
“Aggressive tax deductions”
“They cheated on me, what do I do?”
“Lose even more weight” or
“Unusual cough”
… you don’t need to be Sherlock Holmes to infer the content of the conversation.
But also, the URL of your conversation: every conversation with your favorite AI has a link, and that link (that URL) is also shared with Meta and others.
And, as you can imagine, whoever has the link to “those chats” may end up having the script of the latest seasons of your favorite show: the one you star in.
It depends on the privacy settings of those links.
In Grok's case, the links were public by default at the time of the study and remain so at the time of this newsletter's publication (despite us having warned xAI).
You can check it out in this video:
Nothing to worry about: as shown in the following table, Grok (and other providers) share these links to chats with third parties.
Below, I only summarize a simplified and more understandable version.
Two clarifications:
1.- The study only certifies that the third parties mentioned (Meta, Google, etc.) “have access“ not that they have effectively accessed the indicated data. The study has focused on how accessible what is on this side: the websites of the AI services, not the other.
However, as we will see in a second, from a legal perspective, opening the door to third parties unrelated to your data processing already constitutes, in itself, a serious infringement for AI providers.
Regarding whether those third parties have accessed that data or not, well… everyone will have their own theory here.
2.- The specific access opened to each of those third parties depends 100% on the configuration allowed by OpenAI, Anthropic, xAI, Perplexity.
Do you know WHO it DOESN’T depend on in many cases? YOU.
As seen in the table, in many cases access is enabled regardless of whether you accept or not cookies, use ad-blockers, VPNs, or other browser protections.

A few seconds of reflection:
We trust that “our small pieces of information, shared (today) with different services (and tomorrow, with AI agents), will not be aggregated and linked to create an invasive model that violates our privacy.”
This is the classic “trust premise” enshrined by Frank Pasquale ten years ago.
Premise that is infringed millions of times a day in the adtech context.
The real risk is not in each of the scattered crumbs, but in the “mosaic” that forms when they are joined together.
And with the findings revealed today, it becomes apparent even to the most skeptical user that AI has put its formidable capabilities, among “others”, also at the disposal of the programmatic digital advertising machinery, one of the most powerful control structures of this sorry times.
2.- Explanation of the technical part: How does all this work?
This is the boring part, because unlike Meta’s localhost mess that was -let’s face it- a clever technical idea -for evil, but a clever technical idea-, on this occasion OpenAI, Anthropic, xAI, Perplexity have not invented anything new at all.
“URLs”, “Permalinks”
Conversation URLs usually work as permanent links (permalinks) with weak access controls.
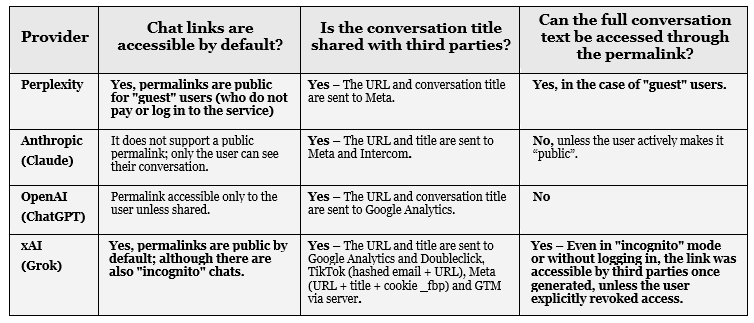
In Grok, permalinks are accessible by default and guest chats are always public.
In Perplexity, Claude, and ChatGPT, permalinks are only visible to the user unless explicitly shared, but once shared, anyone with the link can access the content.
Explanation: If you copy the URL or web link of a conversation with ChatGPT or Claude and paste it into a different browser, you will get an error -unless you have accessed your account with your login and password in that new browser-.
That was not the case with Grok: when you pasted the URL or web address into a different browser (or in the same one, but in a new tab in “incognito mode”), you accessed your conversation.
That means anyone with access to that web address could also see it.
You, your boss, your ex-girlfriend, or anyone else.
Blatantly ignoring cookie consent:
In the indicated cases, trackers are activated regardless of whether the user accepts or rejects non-essential cookies.
For example, in ChatGPT and Grok, information is always sent to Google Analytics.
In Claude, server-to-server tracking only activates if non-essential cookies are accepted, but Meta’s Pixel loads regardless of consent.
Persistent cookies and Server-side tracking:
Cookies are not the trivial matter that the advertising industry has managed to make them out to be: they are like a barcode tattooed on your forehead. You don’t see it—persistent cookies aren’t easy to delete—and it singles you out with a unique digital footprint among all other users on the internet.
In the case of Meta (Facebook/Instagram) and TikTok, these codes are called `fbp` and `ttp` respectively.
With them, we are “marked” as if we were livestock at the BigTech fair.
Every time you visit a webpage that has Meta’s or TikTok’s “pixel” installed, these identifiers are read and sent to their servers. Thus, the company recognizes you as the same person who visited a clothing store yesterday, read a news article today, and is now using an AI chatbot, even if you haven’t logged into Facebook or TikTok.
How do they manage to receive your data even if you use ad blockers or take the trouble to reject cookies?
This is where “server-side tracking” comes in.
Your ability to block the sending of your information through cookies or pixels begins and ends with your browser. If the information is resent to third parties, not through your browser but from the server (”the cloud”), your controls can do nothing.
Companies like Anthropic (Claude) and xAI (Grok) use specific domains so that the cookies downloaded are considered “first-party” (from Anthropic or xAI). From that domain, your information is sent to conversion APIs (from Meta, TikTok, etc.), bypassing any protective action you can take in your browser.
Your browser only sees the connection with the provider’s own domain (Claude, Grok), and ad blockers or privacy extensions cannot intercept the traffic, which they would do if the real destination were not hidden.
Even if you go to the trouble of closing the shutters and windows of your house, these jerks come in through the chimney.
If this topic interests you (and it should), read, read Cristiana Santos.lean, lean a Cristiana Santos.
So what now?
When you write a prompt, the information (such as the permanent link to your chat, the conversation title, or even your email address) is automatically sent to third parties.
And the worst part is that, by combining the persistent cookie (`fbp` or `ttp`) with this data, companies can link your real identity with your content: your private conversations, even if you used the chatbot in incognito mode or without registering.
The `fbp` and `ttp` cookies are tattoos that identify you while browsing the web, and server-side tracking is a technical trick that prevents traditional privacy tools from blocking the flow of this data. Together, they manage to transform the conversations you believe to be private into valuable information for personalized advertising, analysis of your behavior, and enriching your user profiles in their hands.
None of this is new in the world of advertising; what is new is that it has been integrated in a hidden (and rapid) way into AI chatbots: contexts that are currently on the rise and particularly attractive because both you and I let our guard down in them.
Now let’s move on to the legal qualification of all this.
3.- What legal obligations have been breached here?
The analysis is generic because there are many breaches of varying scope, as shown in the previous table.
We will focus on “the big stuff”:
From the perspective of personal data protection legislation (GDPR in the EU), the user interacts or chats with the AI model for the purpose of obtaining answers to their questions or requests, whatever they may be.
When OpenAI, Anthropic, Perplexity, or xAI make user data related to these chats available to third parties, both (i) the mere act of making it available and (ii) the eventual access by said third parties are distinct processes that have nothing to do with what the user expects and with the service that is the subject of the contractual relationship with the user.

Therefore, AI providers are legally obliged to:
a. Inform about their processing in a clear and understandable manner
The legitimate expectations of the user hardly include the possibility that their conversations will be accessible to third parties such as Meta or Google.
The four companies use generic and ambiguous expressions to refer to the user’s prompts without specifically mentioning them when informing about third-party access: “user content” (OpenAI), “conversations” (Anthropic), “service interaction info” (Perplexity), and “user info” (xAI).
This is like “we will use your data to personalize your experience,” which can mean a hundred things and none, and has been specifically sanctioned by the AEPD.
The information should enable the data subject to understand what the hell is going to be done with their data.
And this information must be provided in a very specific way.
Not only the EDPB, but also the CJEU literally in paragraph 54 of its 2024 Meta Platforms Ireland (C-757/22) judgment imposes the obligation of the controller to inform the data subject in the following terms:
“The GDPR imposes an obligation on the controller, where personal data are collected from the data subject, to inform the data subject of the purposes of the processing for which those data are intended along with the legal basis for that processing and of the recipients or categories of recipients of those data, respectively.” (paragraph 54).
It is significant that even when OpenAI does offer this structured and linked information in accordance with the above, it does not refer to the practices observed in this study.
In short, these four companies, instead of complying with their transparency obligation, abuse the complexity of their privacy policies to overwhelm us with long texts and abstract concepts, omitting the key point that anyone could understand: that they provide personalized advertising giants with the topics of your conversations with their AI chats, and in some cases, the entire text of them.
In my humble opinion, this is something that deserves the same relevance as the ubiquitous “AI makes mistakes, check our responses” that is not missing from any interface to mitigate responsibilities if things go wrong.

b.- Having a legal basis for personal data processing
.- Having a specific legal basis for these processing operations (the same applies to third parties accessing this data for their own purposes).
This basis cannot be, as we say, the “performance of the contract between the user and the AI provider”.
It is debatable whether the training of the service itself with the user’s interactions are “objectively necessary” for the provision of the service (not in vain these companies swear and forswear that they do not train with the interactions, inputs and outputs of their users in the professional and corporate segments, so it is difficult to be indispensable with others what is not done with some).
What is indisputable is that opening access to third parties for purposes unrelated to the operation of the tool through mechanisms of adtech can be legitimized via contract.
This would only be possible through explicit consent (formula advocated by the EDPB) or legitimate interest (but the information about the processing and the possibility of exercising a right of opposition are conspicuous by their absence).
Additionally, this data processing must be covered by some exception to the prohibition of processing special category data.
It is a known and massive practice among users (and encouraged by providers) that users make inquiries about their health, psychological state, intimate matters...
It is precisely this fact that makes the results of this study so disturbing.
The longitudinal processing of these conversations over a significant period allows for the inference of all kinds of special category data such as religious and political ideology or the sexual orientation of the data subjects.
SRB / Scania doctrine?
The “silver bullet” used by these providers in this type of scenario (the scenario I am referring to is the one where “you’ve been caught with your hand in the cookie jar”) is one of two:
(i) anonymization or
(ii) pseudonymization (”de-identification” as they say in the USA) that prevents the recipient of the data from re-identifying users without disproportionate efforts in terms of time, material resources, or personnel (SRB / Scania doctrine).
The first thing to make clear is:
Even if any of these arguments were to save the legal basis (I wouldn’t bet a cent on this), the obligation to inform users about this third-party access has been completely ignored.
Now let’s see:
a.- Anonymization:
The robustness and effectiveness of any anonymization process can only be assessed on a case-by-case basis, and it would be necessary to see what each of these companies understands by anonymization, and whether what has been done is sufficient.
b.- Pseudonymization / SRB-Scania doctrine:
You will find few professionals more enthusiastic than me in finding suitable use cases to apply the Scania doctrine.
That said, it does not seem that the two global big data giants (Meta or Google) could benefit from this doctrine in any case, given their vast databases of personal data and their business model.
It should not be forgotten that the “insignificant risk of re-identification of the data subjects” (the cornerstone of this doctrine) must be assessed in light of the “context, purpose, and effects” of the processing carried out by the party accessing the pseudonymized data.
These companies literally live off combining different data sources to better personalize the targeted advertising contracted by their clients.
Spare me that, Meta and Google.
Lastly: What if “it has all been a misunderstanding” and Meta and Google had access but never read the data “wrongly made available to them”?
This says nothing about the responsibility of OpenAI, Anthropic, Perplexity, or xAI.
The mere fact of including tracking pixels on the website is a conscious design decision: allowing certain third parties access to certain personal data of your users for certain purposes.
We have seen this movie many times before: it was clearly stated by the CJEU in 2019 in Fashion ID (C-40/17) and in Wirtschaftsakademie (C-210/16).
In both cases, the third party was Facebook, and joint responsibility for the processing was found: the websites that embedded the pixel or allowed data processing by Facebook had to inform their users about this access, regardless of whether Facebook only processed data from its own users or did not allow the website owner reciprocal access to the obtained data (but only access to aggregated statistics).
“Moreover, by embedding that social plugin on its website, Fashion ID exerts a decisive influence over the collection and transmission of the personal data of visitors to that website to the provider of that plugin, Facebook Ireland, which would not have occurred without that plugin.” (Fashion Id, paragraph 78).
Consequently, the need for a legal basis on the part of the AI provider stems from the decision to embed the tracking pixel, regardless of whether such data is then accessed or used or not, which will be considered when assessing the responsibility of the transferee, if applicable.
Jorge García Herrero
Lawyer and Data Protection Officer
I'm glad you laid this out. But I have so many questions, chief among them being, if they're inserting cookies on user devices without consent and sharing that data with FB, Google, Intercom, etc, how did this go so long before being detected?
Also, is this also the case for the various desktop apps from the LLM providers?
It's exactly like I said a year ago. The moment anyone is using an AI, the machine already creates a de facto tracking system underneath your prompt, breaching GDPR and other privacy laws. There is no written consent clearly stated to the users and certainly no disclaimer that the information will be collected, sent, used by unauthorised third parties, those itself constitute a data breach. But hey.... For AI evangelists it's a must to use AI no matter what.