

¿Cueces o enriqueces? La sentencia Coyote System del TJUE
Y no hablamos de pastillas de caldo
Escribo esto el martes al comprobar que la gente no percibe la importancia de las sentencias C-188/24 (WebGroup Czech Republic) y C-190/24 (Coyote System) del TJUE. Nota de prensa y enlace a la resolución.
Es el momento de ponerse un poco tremendos:
1.- En octubre de 2021, Frances Haugen se sentó ante el Comité de Comercio del Senado de Estados Unidos y reveló miles de documentos internos de Meta.
Los más demoledores describían lo que la compañía sabía y ocultaba sobre el impacto de su algoritmo de recomendación en adolescentes. Las investigaciones internas de Instagram concluían que el sistema redirigía a chicas jóvenes hacia contenido relacionado con trastornos alimentarios y misoginia, aunque no lo buscaran activamente.
2.- Los documentos revelados por Meta en el contexto de un litigio en Nuevo México revelan -lo contamos en marzo- que la compañía conocía que su algoritmo sugería cuatro veces más cuentas de menores de edad a adultos potencialmente peligrosos (proclives a hacerles grooming y sextorsión).
Casi uno de cada cuatro de estos adultos (atención: uno de cada cuatro (¡!!) lo intentaron efectivamente (el dato resulta de los documentos).
¿Meta corrigió a consecuencia de estos datos?
No.
Meta revisó los hechos y no cambió el algoritmo: no es un bug sino un feature cuando tu objetivo último es la optimización del engagement, y el engagement aumentaba con estas prácticas.
Lo peor es que no hace falta recurrir a documentos filtrados, si uno tiene ojos en la cara.
3.- La semana pasada, una chica de 15 años describió en The Guardian el contenido que encuentra en Instagram y TikTok sin buscarlo: comentarios sobre el cuerpo de otras chicas, vídeos con bromas degradantes, material que trivializa la violencia doméstica o la violación. Cuenta cómo intenta activamente evitarlo, pero lo encuentra de forma incesante en cuanto abre sus aplicaciones.
Es el mismo fenómeno documentado por Frances Haugen con slides corporativas, pero que a mí personalmente me impacta mucho más en las palabras de esta joven.
Los sistemas de recomendación de estas plataformas no rankean lo que el usuario quiere ver, sino el contenido que conocidamente aumenta el tiempo “invertido” de pantalla. El engagement es el objetivo, pero se consigue a lomos de material que genera emociones y reacciones fuertes -indignación, comparación social, miedo…-.
Si tuviera Instagram, el artículo de The Guardian (o más bien el post de algún bro riéndose de él) me aparecería de lo primerito en el feed.
4.- El TJUE acaba de declarar que si una plataforma utiliza un algoritmo para determinar, en su propio interés o en el de su servicio, las condiciones, la forma o el orden de prioridad con que se difunde o muestra la información de sus usuarios, está ejerciendo un control activo sobre el contenido.
Y ese control le priva, según el TJUE, de la exención de responsabilidad prevista en la Directiva de ecommerce para las plataformas que alojan contenidos de terceros.
El algoritmo de recomendación destruye la neutralidad del intermediario respecto al contenido alojado por sus usuarios. Eso incluye:
Los memes racistas que ven tus hijos en Instagram, Youtube y TikTok.
El contenido irrelevante que te devuelve Google.
Los productos chungos, caretes, pero “recomendados” en Amazon.
Los evidentes intentos de estafa que te muestra Twitter. Y las paridas de Elon.
El piso más caro (pero que aparece antes) en Idealista o AirBnb.
Las AI slop songs que te empluma Spotify because why not.

En palabras del TJUE:
111 ahora bien, tal y como ha señalado, en esencia, el Abogado General en el punto 239 de sus conclusiones, es precisamente mediante el algoritmo utilizado como dicho operador ejerce un control sobre la información almacenada. Siempre que haya predeterminado, mediante dicho algoritmo, las condiciones para la difusión o no de dicha información, es irrelevante que dicho operador no realice por sí mismo intervenciones adicionales que tengan por efecto promover, modificar o suprimir la información almacenada con vistas a su difusión.
112 A este respecto, conviene precisar que, si, más allá de una simple categorización e indexación de la información con el fin de facilitar su acceso, el algoritmo utilizado determina, en interés del operador o de su servicio, en qué condiciones, de qué manera y con qué orden de prioridad se difunde o no dicha información, dicho operador ejerce un control sobre la misma, de modo que el servicio que ofrece no puede calificarse de «servicio de la sociedad de la información consistente en el almacenamiento de información facilitada por un destinatario del servicio», en el sentido del artículo 14, apartado 1, de la Directiva 2000/31 (véanse, en este sentido, sentencias de 23 de marzo de 2010, Google France y Google, C‑236/08 a C‑238/08, EU:C:2010:159, apartados 115 y 117; de 12 de julio de 2011, L’Oréal y otros, C‑324/09, EU:C:2011:474, apartado 116, así como de 22 de junio de 2021, YouTube y Cyando, C‑682/18 y C‑683/18, EU:C:2021:503, apartado 114).
5.- Last, but not least: que la verificación de edad -una de los temas recurrentes en este newsletter por las peores razones posibles- haya sido la excusa para que el TJUE haya emitido este totémico fallo, es un plot-twist digno de M. Night Shyamalan.
El martes fue un día histórico. Queda ver cómo evoluciona la cosa.
Porque a nadie se le escapa que Schrems II sirvió para muy poco.

Estás leyendo ZERO PARTY DATA. La newsletter sobre actualidad y derecho tecnológico de Jorge García Herrero y Darío López Rincón.
En los ratos libres que nos deja esta newsletter, resolvemos movidas complicadas relacionadas con la normativa de protección de datos personales e inteligencia artificial. Si tienes de alguna de esas, haznos así con la manita. O contáctanos por correo en jgh(arroba)jorgegarciaherrero.com
🗞️Noticias del Mundodato 🌍
.- La Autoriteit Persoonsgegevens neerlandesa multó a la app de transporte Yango con 100 millones de euros por transferir datos personales de usuarios y conductores a Rusia sin las salvaguardas adecuadas (ja, como si hubiera salvaguardias adecuadas si vas a trasnferir datos a Rusia).
Las cláusulas contractuales tipo (SCCs) pretendían compensar las deficiencias apreciadas con medidas de seudonimización y cifrado, pero la Autoridad detectó que hasta noviembre de 2023 las claves de cifrado se almacenaban en los mismos servidores rusos que los datos cifrados. Además, Yandex.Taxi LLC —que controlaba el software y determinaba qué datos se recogían— fue calificada como corresponsable del tratamiento, invalidando incluso el modelo de SCCs utilizado.
.- Corea del Sur impone a Coupang una multa de 408 millones de dólares por la mayor filtración de datos de la historia del país. La Comisión de Protección de Información Personal (PIPC) investigó una brecha que expuso los datos de millones de clientes del gigante del e-commerce, el equivalente coreano de Amazon. La sanción supone un record de sanción en la aplicación de la ley de privacidad coreana PIPA (y en Asia en general). La PIPC determinó que Coupang incumplió sus obligaciones de seguridad técnica y organizativa, así como los deberes de notificación y gestión del incidente.
.- Starmer sigue en su cruzada personal de atajar los males digitales a los niños británicos. Ahora en forma de repetir lo que los australianos hicieron con resultados mixtos: prohibir redes sociales hasta los 16 años. ¿Qué podría malir sal (otra vez)?
Y anunciando el “baneo” de redes en las propias redes, y con mensaje adaptado al formato de las mismas (y con nota de la comunidad con más sentido común que el que gasta cargo público promedio).
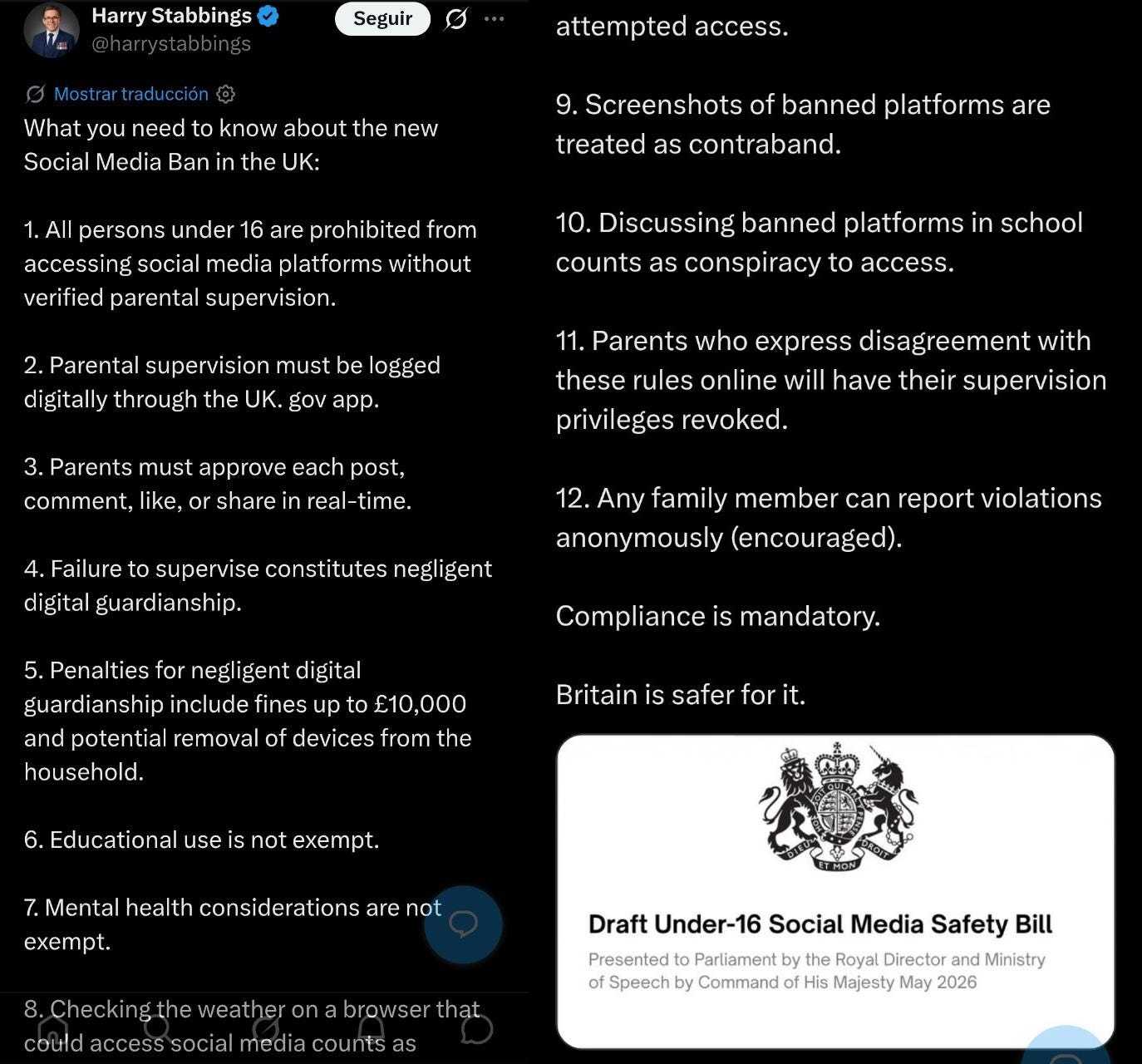
Y con meme instantáneo de menor valorando el asunto, tal cual lo paso en Australia. ‘I’d Stare at a Wall!’ ¿Resignación estoica o sarcasmo legendario?
.- Teams se quedó grabando tras el fin de una reunión, capturando conversaciones privadas de una trabajadora con más de veinte años de antigüedad. La empresa utilizó esos fragmentos meses después para cuestionar su confianza.
La trabajadora, responsable de renta fija en un grupo financiero, solicitó la resolución de su contrato al amparo del artículo 50 del Estatuto de los Trabajadores alegando un progresivo vaciado de funciones y la vulneración de sus derechos fundamentales.
El Juzgado de lo Social inicial desestimó la demanda de la trabajadora. El TSJ del País Vasco revocó completamente ese pronunciamiento: la grabación involuntaria al no cerrar Teams no puede equivaler a la renuncia de la trabajadora a sus derechos fundamentales, ni permite a la empresa valerse de esas comunicaciones. La sentencia aprecia vulneración del derecho a la intimidad, al secreto de las comunicaciones y a la protección de datos, e impone una indemnización total de 335.992,62 euros.
El plot twist procesal : la misma conducta que el juzgado de instancia calificó de mala fe de la trabajadora fue reencuadrada por el TSJ como incumplimiento grave y culpable de la empresa. Via Francisco Trujillo y Ramón Arnó.
.- La victoria parcial de TikTok en el High Court irlandés no implica que sus transferencias de datos a China sean conformes al RGPD: el tribunal confirmó la violación del Capítulo V, pero anuló las órdenes correctoras del DPC por falta de motivación técnica suficiente.
La DPC no justificó por qué las medidas del “Project Clover” eran insuficientes para impedir la reidentificación, pese a disponer del informe Mittal y del terecero independiente NCC Group, ambos favorables a TikTok.
El caso regresa ahora al DPC para que realice ese análisis. El punto no obvio: el tribunal no cuestionó la idoneidad técnica de Project Clover, sino la calidad argumentativa de la decisión regulatoria; la DPC podría reiterar exactamente la misma conclusión si la justifica con rigor metodológico.
TikTok: Lo que funciona y lo que no funciona en el teatro Kabuki de las transferencias internacionales de datos

Lo llaman “sesgo del coste hundido”: como ya perdí medio fin de semana en estudiarme la sanción de la DPC a TikTok en su día, no podía no hacer lo mismo con la sentencia de la semana pasada que la revisó.
.- Un tribunal de Múnich ha declarado a Google responsable de las respuestas incorrectas proporcionadas por su herramienta AI Overviews.
No ha sido una buena semana para la BigTech, no. El fallo establece que, dado que Google despliega y controla el sistema de IA, es responsable de la información errónea que genera, con independencia de que el contenido provenga de un modelo probabilístico. La sentencia no entra en el RGPD al no tratarse de una persona física, pero sí reconoce la vulneración del derecho general a la personalidad corporativa. La consecuencia de mayor alcance: el tribunal equipara el despliegue de un LLM al ejercicio de una actividad editorial, lo que podría transformar la responsabilidad de los proveedores de IA generativa en Europa mucho antes de que el Reglamento de IA sea plenamente aplicable.
📖 Documentos dateros muy cafeteros ☕️
.- ¿No han tenido suficientes disgustos las plataformas en el día de hoy? No: Adrian Todoli tiene otra mala noticia. Y es mala de narices: La dirección algorítmica de la contratista implica cesión ilegal de trabajadores (STS 27/3/2026 – Caso DHL)
.- Las resultonas infografías de Müge Fazlioglu para la IAPP sobre las interrelaciones entre el RGPD y:
- EU AI Act
- Network and Information Security Directive (NIS2)
- Digital Services Act (DSA)
- Digital Markets Act (DMA)
- Data Act, and
- Data Governance Act (DGA)
.- Y la del propio Robert Bateman sobre la resolución original de la DPC sobre TikTok. Todavía era más larga que la resolución del tribunal que devuelve la pelota

Pregúntale a Rumpel
Rumpelstilstskin (“Rumpel” para los amigos) es nuestro asistente personal para conejear entre resoluciones, sentencias, guidelines y materiales diversos que funciona en local (sin preguntar a IAs comerciales).
Nos gusta ver si es capaz de responder decentemente a preguntas complicadas.
💀Death by Meme🤣


🤖NoRobots.txt o Lo de la IA
.- Claude Fable 5 vino y como vino, se fue, por obra y gracia del Dorito. Pero en la UE restringimos normativamente la competencia. El chiste se cuenta solo.

.- Simon Willison reflexiona sobre el product-market fit de las herramientas de IA generativa. Argumenta que la mayoría de los productos construidos sobre LLMs todavía no han encontrado su encaje real con las necesidades de usuarios no técnicos. Willison distingue entre adopción por curiosidad o novedad y adopción por utilidad sostenida, señalando que la mayoría de los casos de uso que generan entusiasmo en la industria son protagonizados por desarrolladores que evalúan las propias capacidades de los modelos, no por usuarios finales que resuelven problemas cotidianos. La pieza cuestiona la métrica de "usuarios activos" como indicador de valor real y propone que el verdadero product-market fit en IA se logrará cuando los modelos sean lo suficientemente fiables y predecibles para operar en flujos de trabajo críticos sin supervisión humana constante. El insight no obvio: Willison sugiere que la fiabilidad —no la capacidad— es el cuello de botella real, y que mejorar los benchmarks de rendimiento sin reducir la tasa de alucinaciones no acerca a los modelos al product-market fit.
.-El Parlamento da de paso las enmiendas del RIA. Lo más importante:
Prohibidos los sistemas de IA que generen contenido CSAM o de desnudos, partes íntima o actividades deportivas en horizontal de alguien identificable (si no cuentan con el consentimiento para ello). Y el punto de que aquel provider que se la juegue a usar este tipo de sistemas no permitido de manera general, pueda probar que tiene medidas técnicas reales y efectivas para prevenir que genere este tipo de contenido. Aplicable la prohibición para el deployer, claro.
Los nuevos plazos de aplicación:
a partir del 2 de diciembre de 2027 para los sistemas de IA de alto riesgo autónomos.
a partir del 2 de agosto de 2028 para los sistemas de IA integrados como componentes de seguridad y regulados por la legislación sectorial de seguridad y vigilancia del mercado.
a partir del 2 de diciembre de 2026 para la obligación de incluir marca de agua en los contenidos generados por IA. Mismo plazo para los sistemas de generación de contenido CSAM y desnudil.
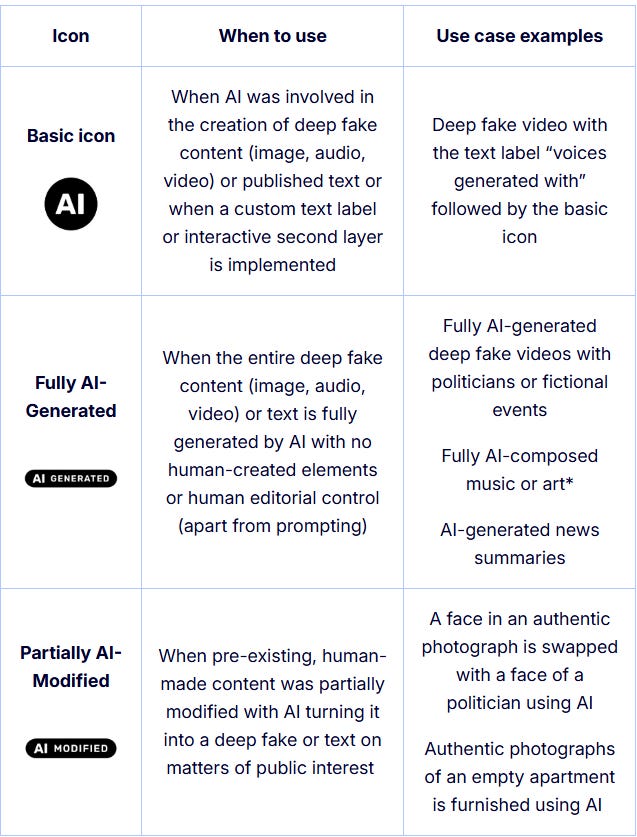
Justo del etiquetado, salieron aquellos iconos propuestos por la Comisión. Lo obligatorio es el etiquetado y marcado legible del artículo 50, pero al menos aquí llegaron más lejos que con los iconos normalizados del RGPD.
.- El EDPS, en formato de post corto del Supervisor, nos recuerda que el shadow AI puede ser una brecha de seguridad curiosa. Que hay que estar al loro de que nadie use ninguna aplicación o servicio con IA no autorizado, y que no está de más meter bloqueo de dominios no autorizados, restricciones en dispositivos corporativos y dar alternativas seguras para hacer eso que el empleado intentaba por su cuenta y riesgo.
.- Sin esperarlo, nos encontramos con un documento de Amnistía Internacional sobre riesgos de la IA generativa. Justo el título llama a lo datero: “Unlawful by design”. Es buen recorrido pro múltiples sesgos, incluyendo determinadas actuaciones de DPAs en casos sonados: que la hegemonía del inglés provoca el sesgo de considerar cualquier información anglo más fiable que el resto, que el opt-out suele funciona vaya, que se genera contenido CSAM a lo loco, que el odio y perjuicio escala con el tamaño del modelo. Y el siguiente caso, que tiene que tela:

🛠️Herramientas útiles
.- Supertonic es una herramienta de Supertone para manipulación y transformación de voz con IA, publicada como proyecto open-source en GitHub. La herramienta permite modificar características vocales —tono, timbre, estilo de habla— mediante modelos de síntesis y conversión de voz de alta calidad, con aplicaciones en producción de audio, accesibilidad y creación de contenido.
.- Markus Sullivan publica en GitHub un repositorio con todos los casos del TJUE sobre protección de datos, las directrices del EDPB y el texto completo del RGPD en formato PDF, listos para descargar sin necesidad de scripts de scraping ni permisos internos. El repositorio está pensado para quienes necesitan esos datos para entrenar modelos, realizar análisis semántico o simplemente tener un corpus legal actualizado disponible offline. Y el post en linkedin, como siempre, es muy grasioso.
🙄 El chorradón final

Si echas de menos algun doc, comentario o chorradón que manifiestamente debería haber estado en el Zero Party Data de la semana, escríbenos o deja un comentario y lo valoraremos para la próxima.