

Every prompt you make, AI´ll be watching you
Oooops, they did it again !!
(English versión here)
Cuando usas un chatbot de inteligencia artificial, lo normal es pensar que lo que escribes queda entre tú y tu proveedor de IA favorito.
Lo que pasa en Las Vegas se queda en Las Vegas y tal.
Y de hecho, los proveedores de IA incentivan que utilicemos sus modelos para integrarlos en nuestras decisiones diarias, para que confiemos en ellos en contextos cada vez más íntimos. Se supone que bajo esa premisa.
Pues no.
Narseo Vallina y sus compañeros de IMDEA NETWORKS lo han vuelto a hacer:
Tal y como desarrollan en esta web, en un estudio realizado en abril pasado, han descubierto cosas que posiblemente te sorprendan y te resulten perturbadoras si chateas con modelos de IA a través de web (no a través de la API).
Modelos como Perplexity, ChatGPT, Claude o Grok.
Poco conocidos. Y que nadie usa.
Te invito a que visites la web original.
Aquí lo único que voy a hacer es lo que hice la última vez (el escándalo del localhost de Meta): traducir lo que han descubierto en términos que un ciudadano lego en tecnología pueda entender.
Primero te cuento lo que han descubierto.
Segundo: te explico cómo funciona, cómo hacen estas cosas estas empresas
Por último, te doy la visión jurídica, que ha sido mi parte en todo esto: las responsabilidades que pueden y deben afrontar estas empresas.

Estás leyendo ZERO PARTY DATA. La newsletter sobre actualidad y derecho tecnológico de Jorge García Herrero y Darío López Rincón.
En los ratos libres que nos deja esta newsletter, resolvemos movidas complicadas relacionadas con la normativa de protección de datos personales e inteligencia artificial. Si tienes de alguna de esas, haznos así con la manita. O contáctanos por correo en jgh(arroba)jorgegarciaherrero.com
¿Qué han descubierto?
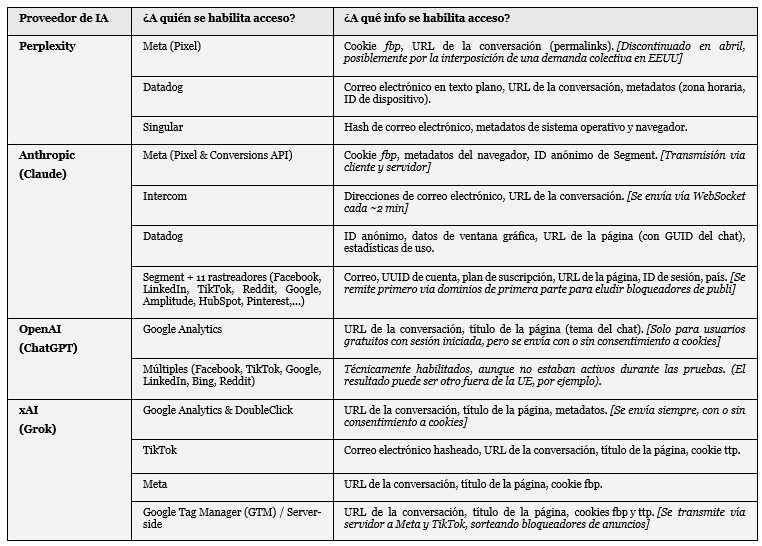
Las webs de estos cuatro servicios tienen puertas abiertas en sus webs que permiten a terceros acceder a tu información:
.- Grok y Perplexity: A través del pixel de Meta
.- OpenAI: A través de Google Analytics .
.- Claude: A través del Meta pixel, y las APIs de conversión de Facebook, Linkedin, TikTok, Amplitude, HubSpot, Pinterest entre otras.
Pero “no se vayan todavía: aún hay más”.
Ajústense los cinturones: esto es algo parecido -al menos para parte de los usuarios- a tener una videocámara apuntando directamente a su diario abierto de par en par.

“Bueno, lo importante es que no tengan acceso a mis conversaciones “privadas” con Claude y ChatGPT, y eso sucede ¿no? ¿NO? ¿EH?”.
También se comparte el “título de cada chat”.
Esto no es muy buena noticia: las IAs tienen la mala costumbre de generar automáticamente un título para la conversación que resume su contenido, de modo que si los títulos de las conversaciones son:
“Consejos depresión”
“Deducciones fiscales agresivas”
“ Me han puesto los cuernos ¿Qué hago?”
“Adelgazar aún más” o
“Tos rara”
… no hay que ser Sherlock Homes para inferir el contenido de la conversación.
Pero es que además la URL de tu conversación: cada conversación con tu IA favorita tiene un enlace, y ese enlace (esa URL), también se comparte con Meta y otros.
Y, como te puedes imaginar, quien tiene el enlace a “esos chats”, puede llegar a tener el guión de las últimas temporadas de tu serie favorita: la que tú protagonizas.
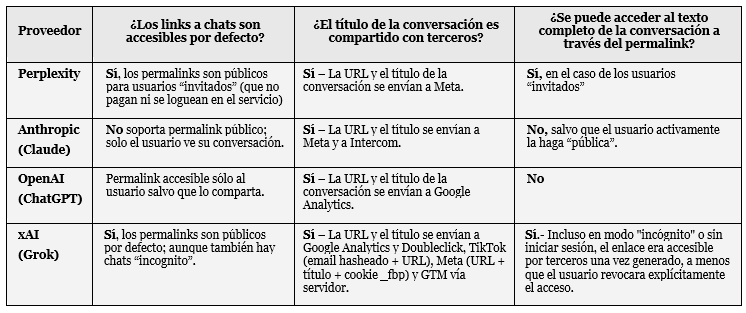
Depende de la configuración de privacidad de esos enlaces.
En el caso de Grok, los enlaces eran públicos por defecto en el momento del estudio y lo siguen siendo en el momento de la publicación de esta newsletter (a pesar de que hemos advertido a xAI).
Puedes comprobarlo en este vídeo:
Nada de qué preocuparse: como se ve en esta tabla, Grok (y otros proveedores) comparten estos enlaces a chats con terceros como Meta y Google.
De nuevo, te animo a que visites la web original, este post sólo pretende explicarla al ciudadano sin conocimientos informáticos.
A continuación sólo resumo una versión simplificada y más comprensible:
Dos matizaciones:
1.- El estudio sólo acredita que esos terceros citados (Meta, Google, etc…) “tienen acceso”, no que lo hayan hecho efectivo, accediendo a los datos indicados. El estudio se ha centrado en lo accesible que es lo que está en esta orilla: las webs de los servicios de IA, no en la otra.
Sin embargo, como veremos en un momento, desde el punto de vista legal, abrir la puerta a terceros que no tienen nada que ver con tu tratamiento de datos, ya constituye por sí una infracción de las gordas para los proveedores de IA.
Sobre si esos terceros han accedido o no a esos datos, bueno… cada cual tendrá su teoría aquí.
2.- El acceso concreto abierto a cada uno de esos terceros depende al 100% de la configuración permitida por OpenAI, Anthropic, xAI, Perplexity.
¿Sabes de quién NO depende en muchos casos? De ti.
Como se ve en la tabla, en muchos casos el acceso se habilita con independencia de que aceptes o no cookies, de que utilices ad-blockers, VPNs u otras protecciones en el navegador.

Unos segundos de reflexión:
Confiamos en que “nuestros pequeños fragmentos de información, compartidos (hoy) con diferentes servicios (y mañana, con agentes de IA), no serán agregados y vinculados para crear un modelo invasivo que viole nuestra privacidad.
Esta es la clásica “premisa de confianza” consagrada por Frank Pasquale hace diez años.
Premisa que es infringida millones de veces al día en el contexto adtech,
El riesgo real no está en cada una de las miguitas dispersas, sino en el “mosaico” que se forma al unirlas.
Y con los hallazgos revelados hoy, se hace patente hasta para el usuario más escéptico que la IA ha puesto sus formidables capacidades, entre otras, también a disposición de la maquinaria de la publicidad digital programática, una de las estructuras de control más poderosas de este siglo.
Explicación de la parte técnica ¿Cómo funciona todo esto?
Esta es la parte aburrida, porque a diferencia de la guarrería del localhost de Meta que fue -reconozcámoslo- una ideaca técnica -para el mal, pero ideaca técnica-, en esta ocasión OpenAI, Anthropic, xAI, Perplexity no han inventando absolutamente nada nuevo.
“URLs”, “Permalinks”
Las URLs de conversación suelen funcionar como enlaces permanentes (permalinks) con controles de acceso débiles.
En Grok, los permalinks son accesibles por defecto y los chats de invitado son siempre públicos.
En Perplexity, Claude y ChatGPT, los permalinks solo son visibles para el usuario a menos que se compartan explícitamente, pero una vez compartidos, cualquiera con el enlace puede acceder al contenido.
Explicación: Si tú copias la URL o enlace-web de una conversación con ChatGPT o Cluade y la pegas en un navegador distinto, te dará error -a menos que hayas accedido a tu cuenta con tu login y contraseña en ese nuevo navegador-.
No es eso lo que pasaba con Grok: al pegar la URL o dirección web en un navegador distinto (o en el mismo, pero en una nueva pestaña en “modo incógnito”), accedías a tu conversación. Eso quiere decir que cualquiera con acceso a esa dirección web iba a verla también. Tú, tu jefe, tu exnovia o cualquiera.
Pasando olímpicamente del consentimiento a cookies:
En los casos indicados, los rastreadores se activan independientemente de que el usuario acepte o rechace cookies no esenciales.
Por ejemplo, en ChatGPT y Grok, el envío de información a Google Analytics ocurre siempre.
En Claude el rastreo servidor-a-servidor solo se activa si se aceptan cookies no esenciales, pero el Pixel de Meta se carga con independencia de que lo consientas o no.
Cookies persistentes y Rastreo via servidor a servidor (Server-side tracking):
Las cookies no son la chorrada que la industria publicitaria ha conseguido trivializar: son como un código de barras que te tatúan en la frente. No lo ves -y las cookies persistentes no son tan fáciles de borrar-, pero te singularizan con una huella digital única entre todos los demás usuarios e internet.
En el caso de Meta (Facebook/Instagram) y TikTok, estos códigos se llaman `fbp` y `ttp` respectivamente.
Con ellas nos “marcan” como si fuéramos ganado en la feria de la BigTech.
Cada vez que visitas una página web que tiene instalado el “pixel” de Meta o TikTok, estos identificadores son leídos y enviados a sus servidores. Así, la empresa te reconoce como la misma persona que visitó una tienda de ropa ayer, leyó un artículo de noticias hoy y ahora está usando un chatbot de IA, incluso aunque no hayas iniciado sesión en Facebook o TikTok.
¿Cómo logran recibir tus datos incluso aunque uses bloqueadores de anuncios o te molestes en rechazar las cookies?
Aquí entra el “server-side tracking”.
Tu capacidad para bloquear el envío de tu información a través de cookies o píxeles empieza y termina en tu navegador. Si la información se reenvía a terceros, no a través de tu navegador, sino desde el servidor (“la nube”), tus controles no pueden hacer nada.
Empresas como Anthropic (Claude) y xAI (Grok) utilizan dominios específicos para que las cookies descargadas sean calificables como de “primera parte” (de Anthropic o xAI). Desde ese dominio, se envía tu información a APIs de conversión (de Meta, TikTok, etc.) eludiendo cualquier acción de protección que puedas utilizar en tu navagador.
Tu navegador sólo ve la conexión con el dominio del propio proveedor (Claude, Grok) y los bloqueadores de anuncios o extensiones de privacidad no pueden interceptar el tráfico, cosa que harían si el destino real no se ocultara.
Aunque te molestes en cerrar ventas y persianas de tu casa, estos capullos entran por la chimenea.
Si este tema les interesa (y debería), lean, lean a Cristiana Santos.
¿Y entonces?
Cuando escribes una prompt la información (como el enlace permanente a tu chat, el título de la conversación o incluso tu correo electrónico) se reenvía automáticamente a terceros.
Y lo peor es que, al combinar la cookie persistente (`fbp` o `ttp`) con estos datos, las empresas pueden vincular tu identidad real con tu contenido: tus conversaciones privadas, incluso si utilizaste el chatbot en modo incógnito o sin registrarte.
Las cookies `fbp` y `ttp` son tatuajes que identifican mientras navegas la web, y el server-side tracking es un artificio técnico que evita que las herramientas de privacidad tradicionales bloqueen el flujo de estos datos. Juntos, consiguen transformar las conversaciones que crees privadas en información valiosa para publicidad personalizada, análisis de tu comportamiento y enriquecer tus perfiles de usuario en sus manos.
Nada de esto es nuevo en el mundo de la publicidad, lo nuevo es que se haya integrado de forma oculta (y tan rápida) en los chatbots de IA: contextos hoy en auge y especialmente llamativos porque en ellos tanto tú como yo bajamos la guardia.
Vamos ahora con la calificación legal de todo esto.
¿Qué obligaciones legales se han incumplido aquí?
El análisis es genérico porque hay muchos incumplimientos de distinto alcance, tal y como resulta de la tabla anterior.
Nos centraremos en “lo gordo”:
Desde el punto de vista de la normativa de protección de datos personales (RGPD en la UE) el usuario interactúa o chatea con el modelo de IA con la finalidad de obtener respuestas a sus preguntas o solicitudes, sean éstas las que sean.
Cuando OpenAI, Anthropic, Perplexity o xAI ponen los datos del usuario relacionados con estos chats) a disposición de terceros, tanto (i) la mera puesta a disposición, como el (ii) eventual acceso por dichos terceros, son tratamientos distintos que no tienen nada que ver con lo que el usuario espera, y con el servicio objeto de la relación contractual con el usuario.

Por tanto, los proveedores de IA están legalmente obligados a :
1.- Informar de sus tratamientos de forma clara y comprensible
Las legítimas expectativas del usuario difícilmente incluyen la posibilidad de que sus conversaciones sean accesibles por terceros como Meta o Google.
Las cuatro compañías utilizan expresiones genéricas y equívocas para referirse a las user prompts del usuario sin citarlas específicamente al informar sobre acceso de terceros: “user content“ (OpenAI), “conversations” (Anthropic), “service interaction info” (Perplexity) and “user info” (xAI).
Esto es como lo de “usaremos tus datos para personalizar tu experiencia” que puede significar cien cosas y ninguna, y ha sido específicamente sancionado por la AEPD.
La información debe permitir al interesado entender qué demonios se va a hacer con sus datos.
Y esta información se debe facilitar de una forma muy específica.
No sólo el EDPB, sino también el TJUE literalmente en el apartado 54 de su sentencia de 2024 Meta Platforms Ireland (C-757/22) impone la obligación del responsable de tratamiento de informar al interesado en los siguientes términos:
“GDPR imposes an obligation on the controller, where personal data are collected from the data subject, to inform the data subject of the purposes of the processing for which those data are intended along with the legal basis for that processing and of the recipients or categories of recipients of those data, respectively.” (paragraph 54).
Es significativo que incluso cuando OpenAI sí ofrece esta información estructurada y vinculada de acuerdo con lo anterior, no hace referencia a las prácticas observadas en este estudio.
En definitiva, estas cuatro empresas, en vez de cumplir con su obligación de transparencia, abusan de la complejidad de sus políticas de privacidad para aturdirnos con largos textos y conceptos genéricos y abstractos, omitiendo el punto clave que cualquiera podría entender: que facilitan a gigantes de la publicidad personalizada los temas de tus conversaciones con sus chats de IA, y en algunos casos, el texto entero de las mismas.
En mi humilde opinión, esto es algo que merece la misma relevancia que el ubicuo “La IA comete errores, comprueba nuestras respuestas” que no falta en ninguna interfaz para mitigar responsabilidades si las cosas van mal.

2.- Dotarse de una base legal de tratamiento
.- Dotarse de una base de legitimación específica para estos tratamientos (idem de los terceros que accedan para sus propios fines a estos datos).
Esta base no puede ser, como decimos la “ejecución del contrato entre usuario y el proveedor de IA”.
Es discutible que el entrenamiento del propio servicio con las interacciones del usuario sean “objetivamente necesarias” para la prestación del servicio (no en vano estas compañías juran y perjuran que no se entrenan con las interacciones, inputs y outputs de sus usuarios en los tramos profesionales y corporativos, así que difícilmente lo que no se hace con unos puede ser indispensable con los otros).
Lo que es indiscutible es que la apertura de acceso a terceros para finalidades que nada tienen que ver con el funcionamiento de la herramienta a través de mecanismos propios de la adtech, pueda ser legitimable vía contrato.
Esto sólo cabría mediante consentimiento explícito (fórmula preconizada por el EDPB) o interés legítimo (pero la información del tratamiento y la posibilidad de ejercer un derecho de oposición brillan por su ausencia).
Adicionalmente, este tratamiento de datos debe venir cubierto por alguna excepción a la prohibición de tratamiento de datos de categoría especial.
Es una práctica conocida y masiva por parte de los usuarios (e incentivada por los proveedores) que los usuarios realicen consultas sobre su salud, estado psicológico, cuestiones íntimas...
Es precisamente este hecho lo que hace tan perturbadores los resultados de este estudio.
El tratamiento longitudinal de estas conversaciones durante un período significativo permite inferir todo tipo de datos de categoría especial como la ideología religiosa y política o la orientación sexual de los interesados.
¿Doctrina SRB / Scania?
La “bala de plata” utilizada por estos proveedores en este tipo de escenarios (el escenario al que me refiero es el de “te han pillao con el carrito del helao”) es uno de dos
(i) la anonimización o
(ii) la seudonimización (“deidentificación” como dicen en USA) que impida al destinatario de los datos reidentificar a los usuarios sin realizar esfuerzos desproporcionados en términos de tiempo, recursos materiales o personal (doctrina SRB / Scania).
Lo primero es dejar claro algo:
Incluso si alguno de estos argumentos lograran salvar la base de legitimación (no apostaría un centavo por esto), la obligación de informar a los usuarios sobre este acceso de terceros ha sido ignorada por completo.
Ahora veamos:
a.- Anonimización:
La solidez y eficacia de cualquier proceso de anonimización sólo puede evaluarse caso por caso, y habría que ver qué entienden cada una de estas empresas por anonimización, y si lo hecho es suficiente.
b.- Seudonimización / doctrina SRB-Scania:
Encontrarán a pocos profesionales más ilusionados que yo en encontrar casos de uso aptos para aplicar la docrina Scania.
Dicho esto, no parece que los dos gigantes mundiales del big data (Meta o Google) puedan beneficiarse en ningún caso de esta doctrina, atendidas sus vastas bases de datos personales y su modelo de negocio.
No se debe olvidar que el “riesgo insignificante de reidentificación de los interesados” (clave de bóveda de esta doctrina) debe evaluarse a la luz del “contexto, finalidad y efectos” del tratamiento realizado por quien accede a los datos seudonimizados.
Estas empresas viven literalmente de combinar distintas fuentes de datos para personalizar mejor la publicidad dirigida contratada por sus clientes.
Así que a otro perro con este hueso, Meta y Google.
Por último: ¿Y si “todo ha sido un malentendido” y Meta y Google tenían acceso pero nunca leyeron los datos “puestos erróneamente a su disposición”?
Eso no dice nada de la responsabilidad de OpenAI, Anthropic, Perplexity o xAI.
El mero de hecho de incluir el tracking pixels en la web es una decisión consciente de diseño: permitir el acceso a determinados datos personales de tus usuarios a determinados terceros para determinadas finalidades.
Esta película la hemos visto ya muchas veces: se declaró con contundencia por el TJUE en 2019 Fashion ID (C-40/17) y en Wirtschaftsakademie (C-210/16).
En ambos casos el tercero era Facebook y se apreció corresponsabilidad en el tratamiento: las webs que insertaban el pixel o consentían el tratamiento de datos por Facebook tenían que informar a sus usuarios de dicho acceso con independencia de que Facebook sólo tratara datos de sus propios usuarios o de que no permitiera al propietario de la web un acceso recíproco a los datos obtenidos (sino sólo a estadísticas agregadas).
Fashion Id:
“Moreover, by embedding that social plugin on its website, Fashion ID exerts a decisive influence over the collection and transmission of the personal data of visitors to that website to the provider of that plugin, Facebook Ireland, which would not have occurred without that plugin.” (78).
En consecuencia, la necesidad de contar con una base legal por parte del proveedor de IA parte de la decisión de incrustar el tracking pixel, con independencia de que luego dichos datos sean luego accedidos o utilizados o no, cosa que contará a la hora de evaluar la responsabilidad del cesionario, en su caso.
¿Y desde la orilla de los destinatarios?
Ciertamente la sentencia del Tribunal Supremo de la semana pasada no podía venir en un momento más adecuado.
El Tribunal Supremo castigaba a una administración por “pedir datos de más a un funcionario” alegando que los principios de limitación de finalidad y privacy by design aplican desde un momento anterior al estricto acceso a los datos, porque de otro modo el derecho de protección de datos se vacía de contenido.
Y lo hace citando al TJUE (si no se adelantaba la barrera de protección a ese momento, la protección a la que tiene derecho el interesado quedaba a expensas de que el destinatario tuviera éxito o no en el intento de acceso a dichos datos.
Jorge García Herrero
Abogado y Delegado de Protección de Datos